はじめに
Emacs内での大規模言語モデル(LLM)との連携は、ここ数年で劇的な進化を遂げてきました。
私の最初のEmacs 内LLMとの出会いは2022年11月、copilot.el によるAI 自動補完でした。このときの感動は鮮明に覚えています。
その後間もなくChatGPT が登場し、ChatGPT.el 等でEmacs内でのAIとの対話ができるようになりましたが、当時は機能も少なく、EmacsでLLMを使うメリットはあまり感じられませんでした。
自分的ブレークスルーは、東京Emacs勉強会 サマーフェスティバル2024 のTomoya さんの発表で ellama を知ったことでした。 ellamaでは従来の対話形式だけでなく、様々な関数を通じてLLMを利用でき、Emacs が何倍も強力な開発環境へと変貌しました。
そして最近では gptel が llm module として doom emacs に正式に組み込まれ、ツール連携やプロンプト/コンテクストエンジニアリング1が非常にスムーズになりました。
これとmcp.el と組み合わせることで、LLM in emacs がある種のplateau に達したのではと感じている今、これを知らないEmacser (同胞) がもしいたら非常に勿体ないと思うので、この記事を書くことにしました。
gptel, mcp.el の設定方法や使う理由、ユースケースなどを紹介します。
gantt
title 私のEmacs 内LLM 遍歴
todayMarker off
dateFormat YYYY-MM
axisFormat %Y-%m
section 自動補完
copilot.el :2022-11, 32M
section 黎明期
ChatGPT.el :2023-03, 17M
org-ai :2023-12, 8M
section 革命
ellama/llm :2024-08, 9M
section 開拓期
ai-org-chat :2024-11, 2M
ob-llm :2025-01, 2M
elisa :2025-03, 1M
copilot-chat.el :2025-03, 2M
section 成熟期
gptel+mcp.el :2025-05, 2M
claude-code.el :2025-06, 1M
- copilot-emacs/copilot.el: An unofficial Copilot plugin for Emacs.
- joshcho/ChatGPT.el: ChatGPT in Emacs
- rksm/org-ai: Emacs as your personal AI assistant
- s-kostyaev/ellama: Ellama is a tool for interacting with large language models from Emacs.
- ahyatt/llm: A package abstracting llm capabilities for emacs.
- ultronozm/ai-org-chat.el
- jiyans/ob-llm
- s-kostyaev/elisa: ELISA (Emacs Lisp Information System Assistant) is a system designed to provide informative answers to user queries by leveraging a Retrieval Augmented Generation (RAG) approach.
- chep/copilot-chat.el: Chat with Github copilot in Emacs !
- karthink/gptel: A simple LLM client for Emacs
- lizqwerscott/mcp.el: An Mcp client inside Emacs
- stevemolitor/claude-code.el: Claude Code Emacs integration
gptel とは
gptelは、Emacsのためのシンプルかつ強力な大規模言語モデル(LLM)クライアントです。 Emacs内のあらゆる場所から自由な形式でLLMと対話できる環境を提供します。 このデモを見ると使用イメージが分かりやすいです。
mcp.el とは
mcp.elは、AIと外部ツールの連携を標準化するオープンプロトコル「Model Context Protocol (MCP)」をEmacs で起動・管理するためのパッケージです。
gptel の設定に (require 'gptel-integrations) を追加するだけで、 ツールに mcp.el を組み込むことができます。
これによりWeb検索、ファイルアクセス、GitHubリポジトリ操作といった様々な機能を備えたMCPサーバーと統一的に通信できるようになります。
gptel の設定例
(use-package! gptel
:config
(require 'gptel-integrations)
(require 'gptel-org)
(setq gptel-model 'gpt-4.1
gptel-default-mode 'org-mode
gptel-use-curl t
gptel-use-tools t
gptel-confirm-tool-calls 'always
gptel-include-tool-results 'auto
gptel--system-message (concat gptel--system-message " Make sure to use Japanese language.")
gptel-backend (gptel-make-gh-copilot "Copilot" :stream t))
(gptel-make-xai "Grok" :key "your-api-key" :stream t)
(gptel-make-deepseek "DeepSeek" :key "your-api-key" :stream t))
mcp.el の設定例
(use-package! mcp
:after gptel
:custom
(mcp-hub-servers
`(("github" . (:command "docker"
:args ("run" "-i" "--rm"
"-e" "GITHUB_PERSONAL_ACCESS_TOKEN"
"ghcr.io/github/github-mcp-server")
:env (:GITHUB_PERSONAL_ACCESS_TOKEN ,(get-sops-secret-value "gh_pat_mcp"))))
("duckduckgo" . (:command "uvx" :args ("duckduckgo-mcp-server")))
("nixos" . (:command "uvx" :args ("mcp-nixos")))
("fetch" . (:command "uvx" :args ("mcp-server-fetch")))
("filesystem" . (:command "npx" :args ("-y" "@modelcontextprotocol/server-filesystem" ,(getenv "HOME"))))
("sequential-thinking" . (:command "npx" :args ("-y" "@modelcontextprotocol/server-sequential-thinking")))
("context7" . (:command "npx" :args ("-y" "@upstash/context7-mcp") :env (:DEFAULT_MINIMUM_TOKENS "6000")))))
:config (require 'mcp-hub)
:hook (after-init . mcp-hub-start-all-server))
(補足)
uvx で起動するmcp server がNixOSで起動しないエラーがありました。
こちらの原因・解決方法は別記事で書いたので、もし同じエラーが出た方はそちらを参照してください。
私が gptel & mcp.el を使う理由
gptel & mcp.el を使う理由は、以下の3点です。
- doom emacs のmodule に組み込まれており、 ほぼカスタマイズなしで 快適に使える
- EmacsのあらゆるbufferでLLMを自由自在に使える
- LLMに対するコントロール性が非常に高い
1と2に関しては書いてある通りですが、3は少し説明が必要かもしれません。
LLM を使うときに我々がコントロールできることは、主に以下の3つだと思います。
- モデル (OpenAI gpt-4.1, Claude Sonnet 4, DeepSeek r1, etc…)
- ツール (Web検索、ファイルアクセス, etc…)
- context (システムメッセージ、過去の会話内容)
LLM の精度を上げるためには、モデルやツールは当然のこととして、contextを適切にコントロールすることが非常に重要です。
例えばLLMは過去の自身の回答内容に捉われたり、コンテクストが長くなるに連れて精度が落ちたりすることが知られています。 (この記事 では AI Cliff と呼ばれています。)
最近ではcontext engineering という言葉が流行っていますが、おそらくこの言葉が出てくるずっと前から gptel には context engineering を簡単に行える機能が備わっています。
以下のユースケースでいくつか紹介しますが、 gptel では、モデルやツールの切り替えはもちろん、過去の会話内容を編集したり、コンテクストを分岐させたりといったことが非常に簡単にできます。
色々なLLMクライアントを使ってきましたが、ここまで簡単にLLMの要素3つをコントロールしやすいものは他に知りません。
ユースケース
基本的な使い方はgptel のREADME に載っているスクリーンレコーディングや 公式youtube を見るのが一番良いです。 日本語だと、この方のブログ記事がとても分かりやすいです: gptel: Emacs上で動作するシンプルなLLMクライアントがとても便利 | DevelopersIO
同じような内容を書いても意味がないので、ここでは上の2ソースで詳しく紹介されていないことに限定して、いくつかの気に入っているユースケースを紹介します。
同一セッション内での複数のモデルを使い分け
対話形式でのセッションはPlain text (org/markdown)のバッファ上で行われるので、 例えば「最初にローカルLLMやコストの小さいモデルで質問し、回答が不十分だったらモデルを切り替えて再度リクエストを送る」のようなことが素早く簡単にできます。
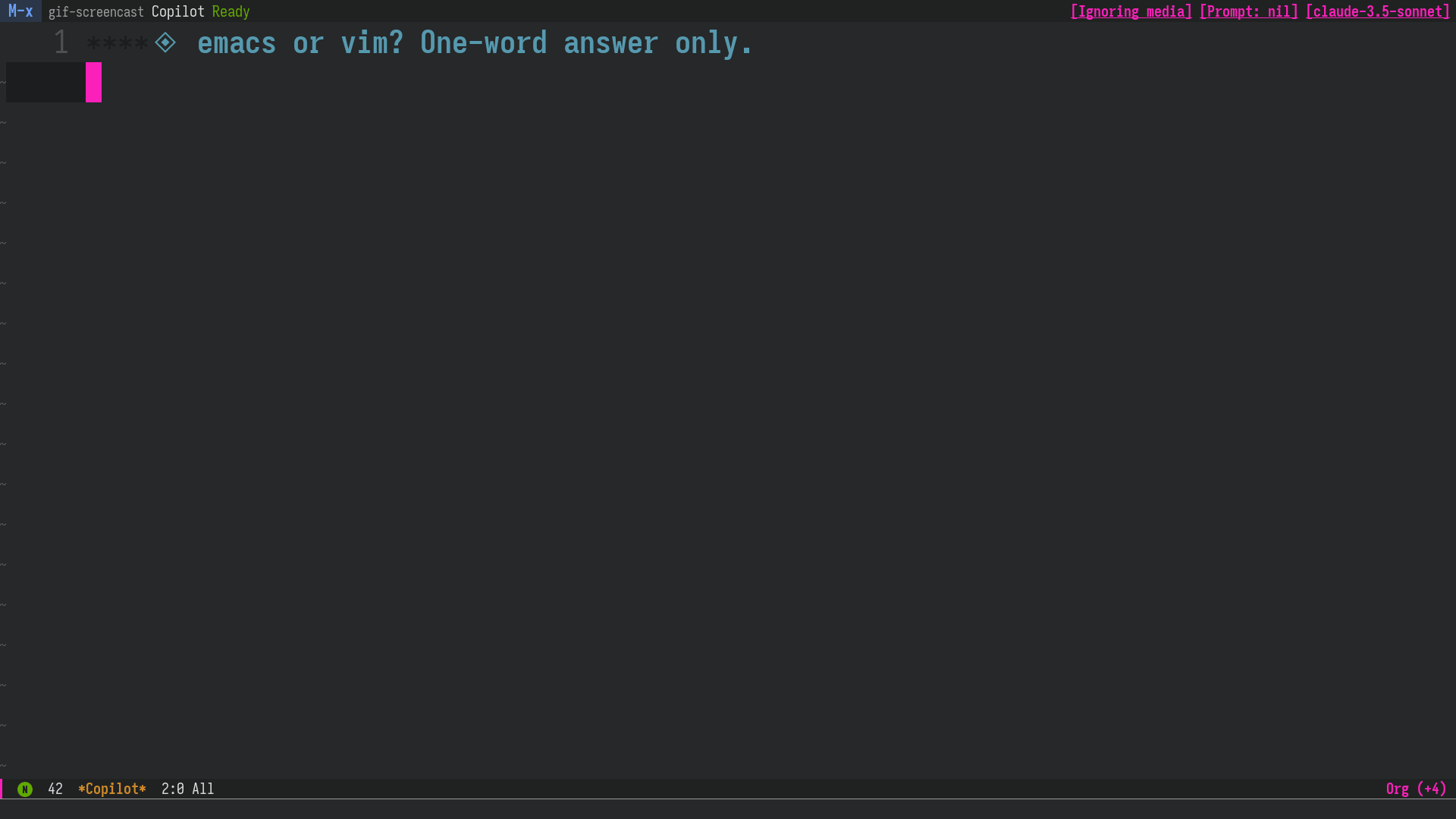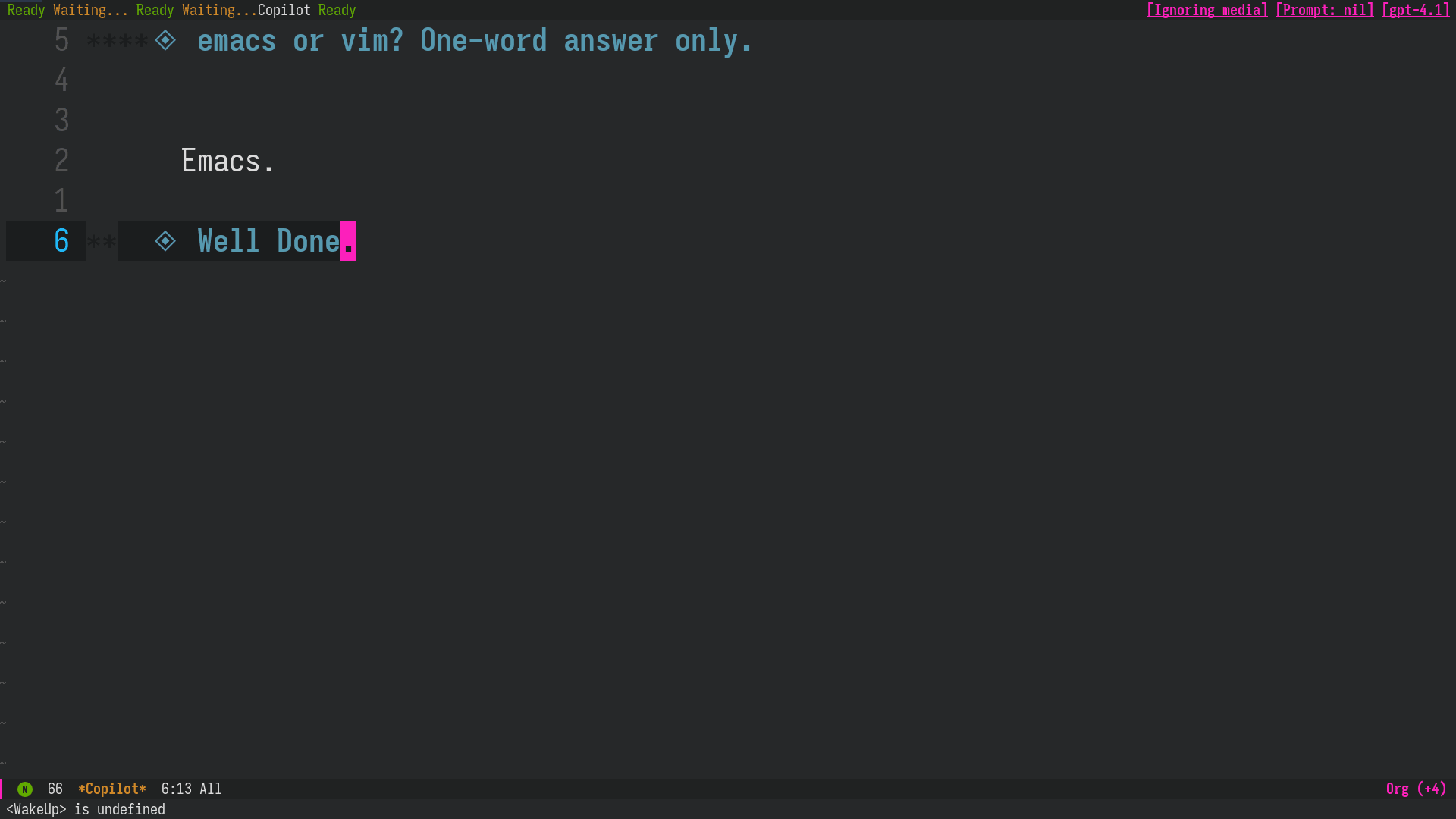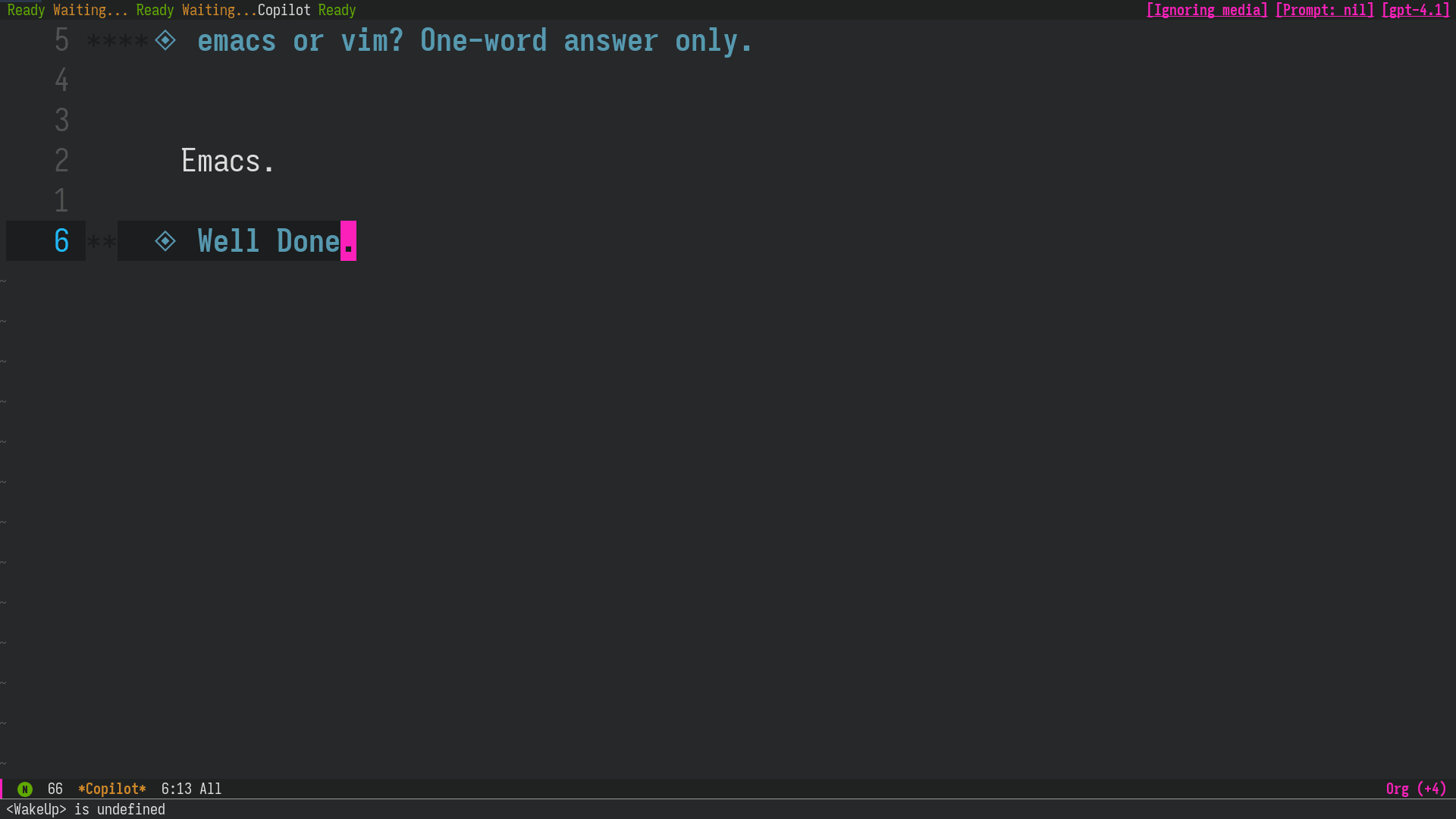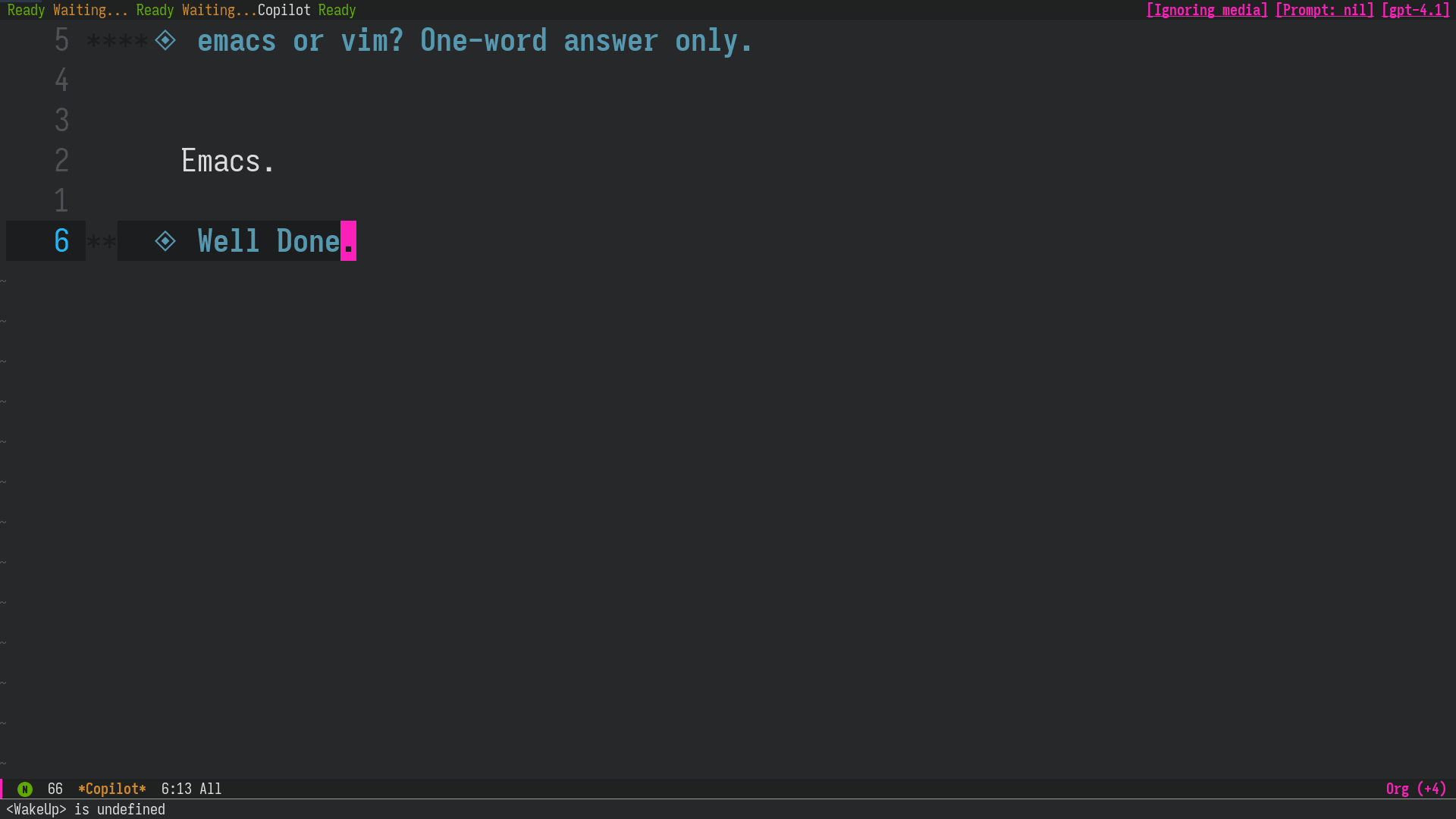
図1: 使用例: Claude Sonnet が間違った回答をしたので、GPT-4.1に切り替えて再度質問
LLMの回答を編集
LLM の過去の回答を削除/編集した上で再度質問することもできるので、会話の流れの軌道修正が簡単にできます。 前のセクション で言及した AI Cliff の抑制にも役立ちます。
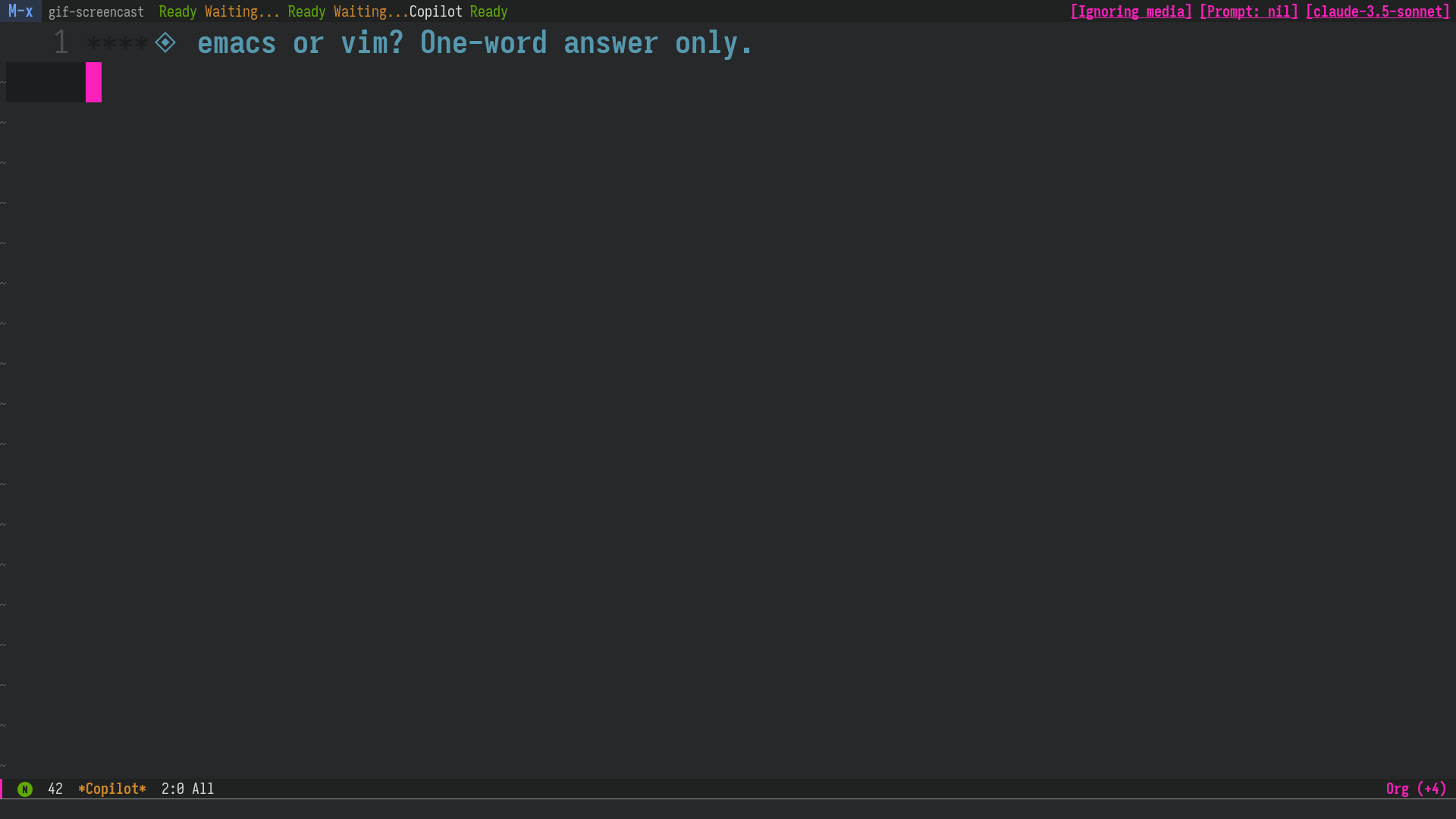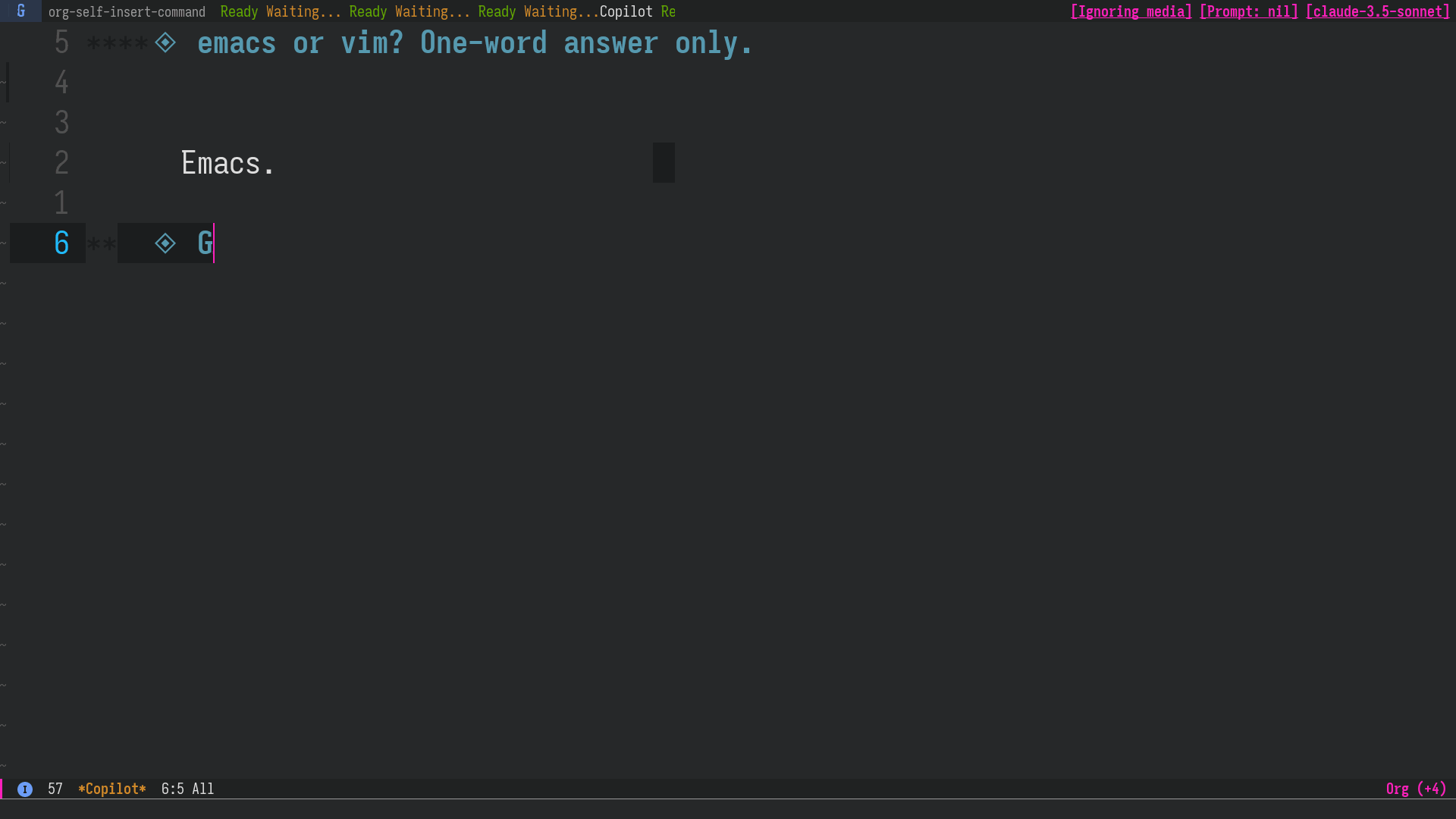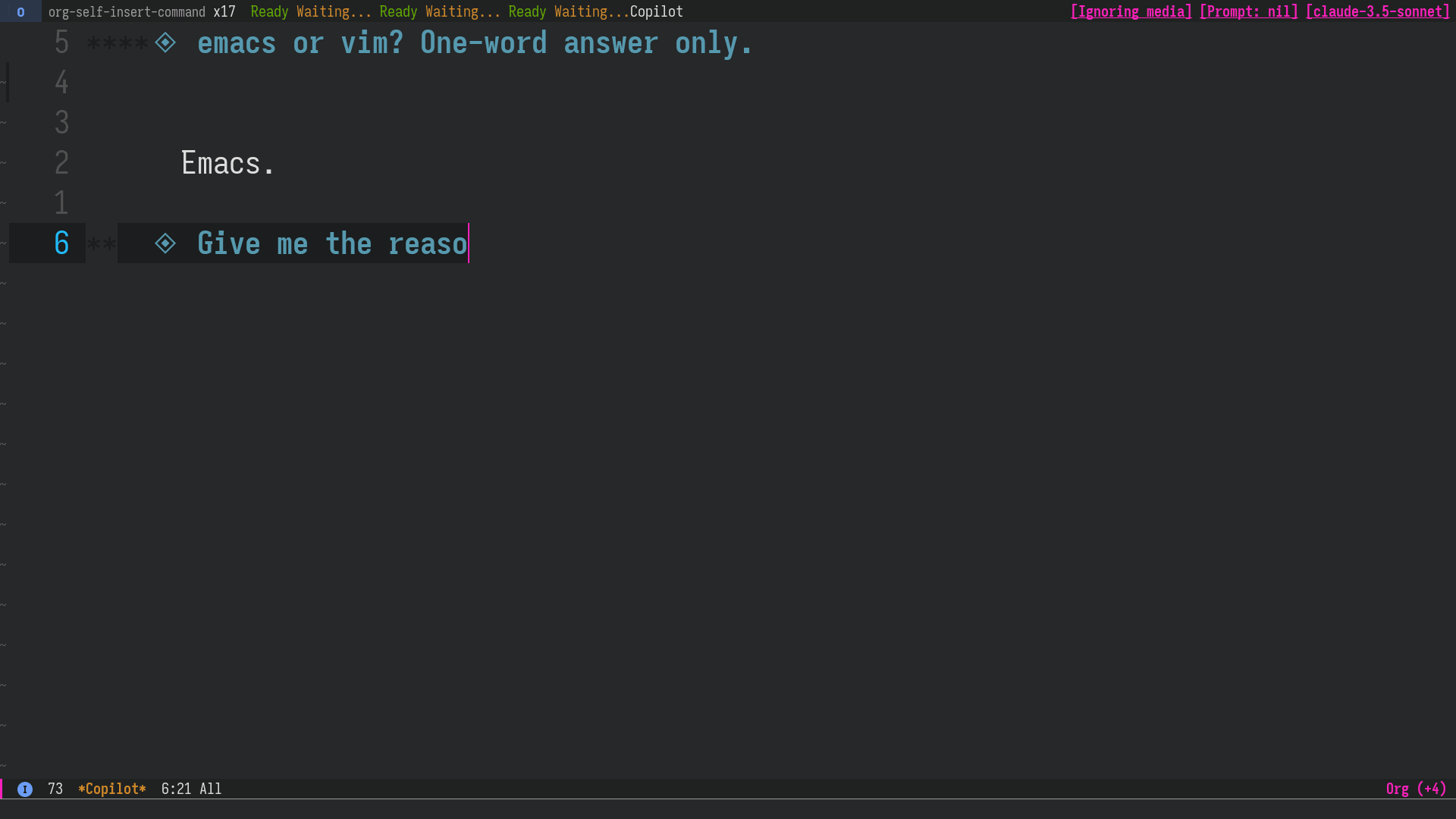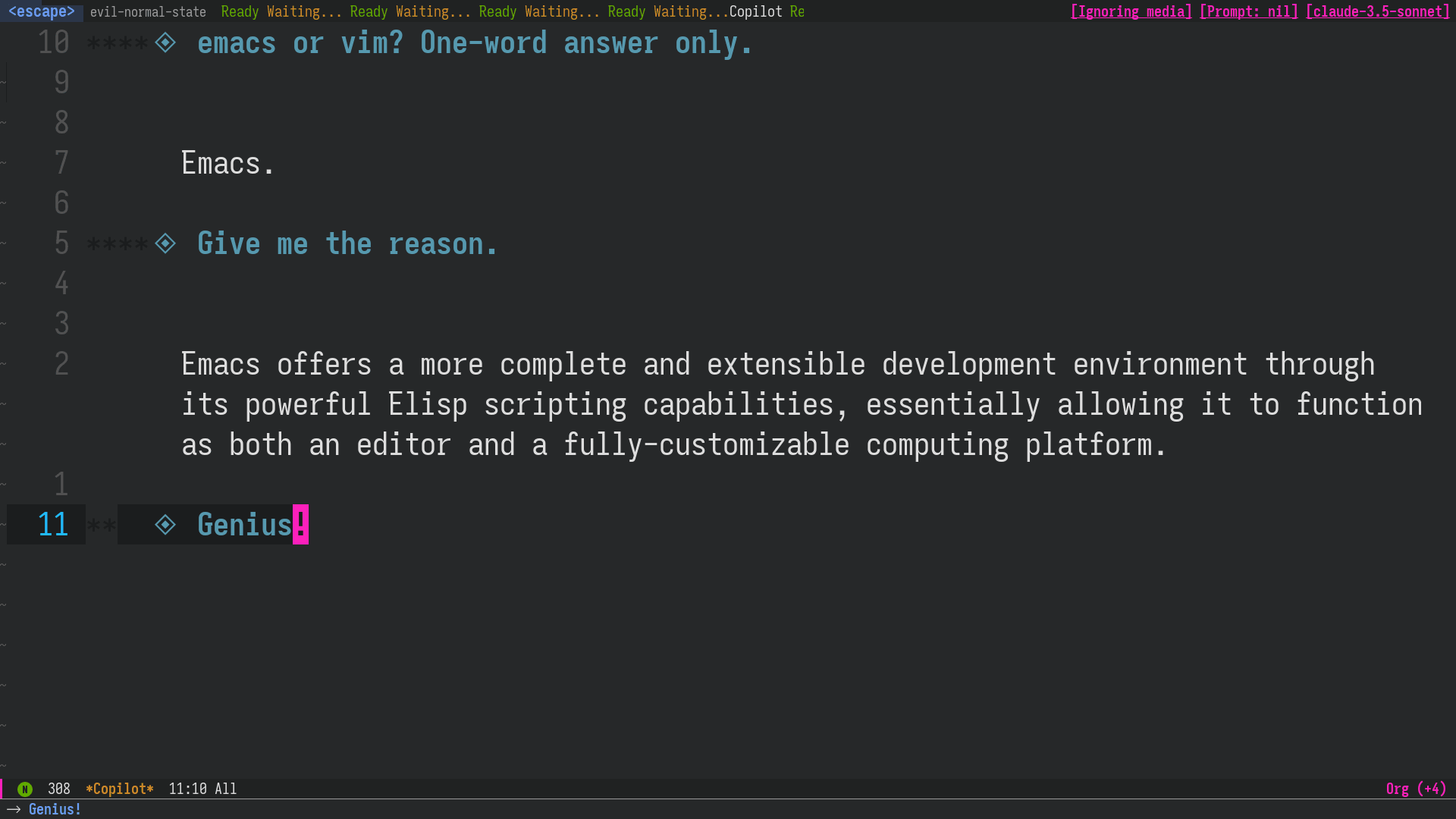
図2: Claude Sonnet の間違った回答をこちらで修正し、あたかも正しく答えてくれたかのように会話を続ける
トピック制限機能
M-x gptel-org-set-topic を使うと、ヘッダーにプロパティを設定して各セクションのコンテクストを制限することができます。

図3: LLMも空気を読む時代。トピック制限をかけて、忖度しない回答を生成。
Context branching
上記のコンテクスト制限を、もう少し構造的に行なうための機能が gptel-org-branching-context です。
例えば特定のドキュメントについて知りたいとき、最上位のヘッダーにそのドキュメントをコピペし、独立な質問を一階層下のヘッダーに書くことで、ドキュメントの内容をコンテクストとして利用しつつ、質問ごとに独立した回答を得ることができます。
* 1st level heading
<全体のコンテクストに入れたい内容>
** 2nd level heading 1
質問1
@assistant
<llm の回答>
*** 3rd level heading
<質問1 に関連した内容の質問>
@assistant
<llm の回答>
** 2nd level heading 2
質問2
ここでのLLMに送られるコンテクストには質問1の内容は含まれず、<全体のコンテクスト>と質問2のみが含まれます。
なお、この機能を使うには、以下のように gptel-org-branching-context を有効にする必要があります。
# Local Variables:
# gptel-org-branching-context: t
# End:
hover している部分の情報を取得
gptel で提供されている関数 gptel-quick を使うと、カーソル位置の情報をLLMに問い合わせることができます。
LSP の hover & describe の機能を全ての場面で使えるようにしたようなイメージです。
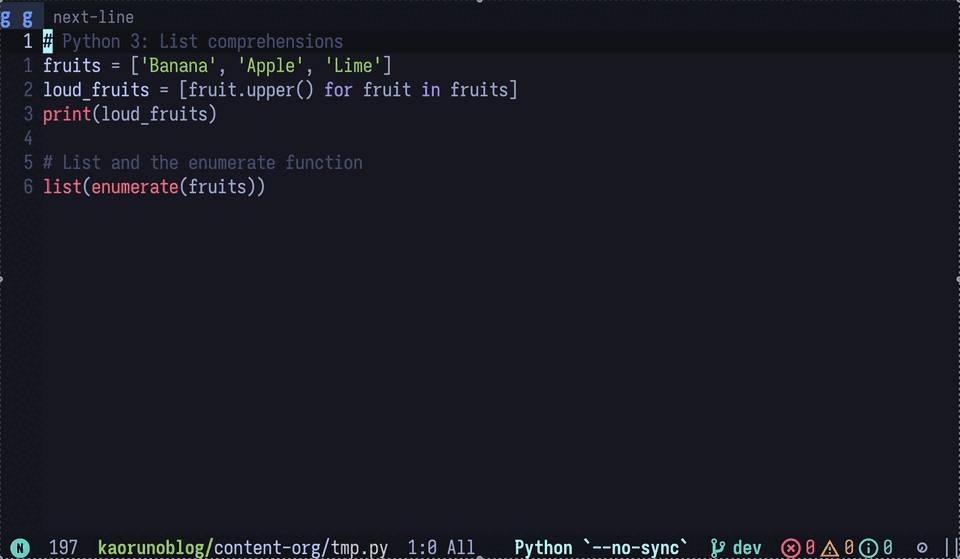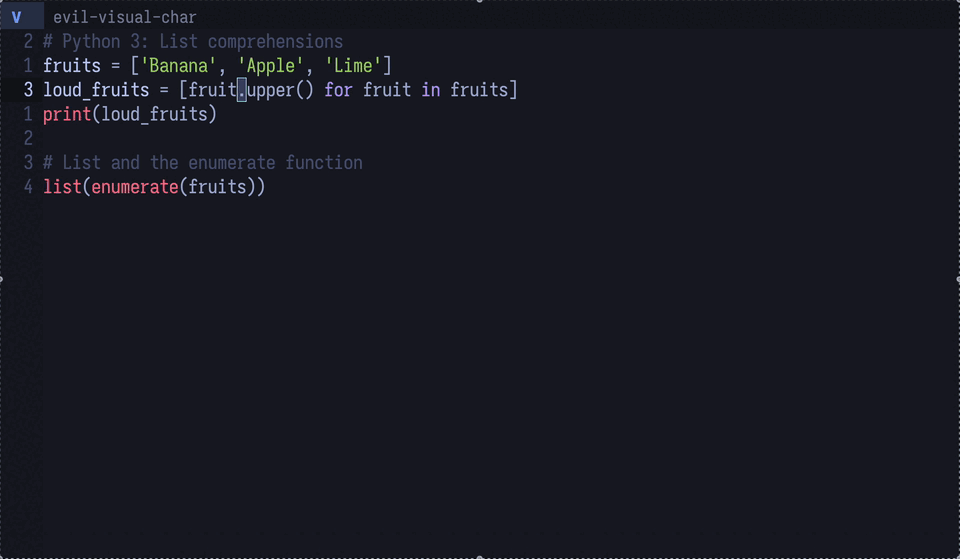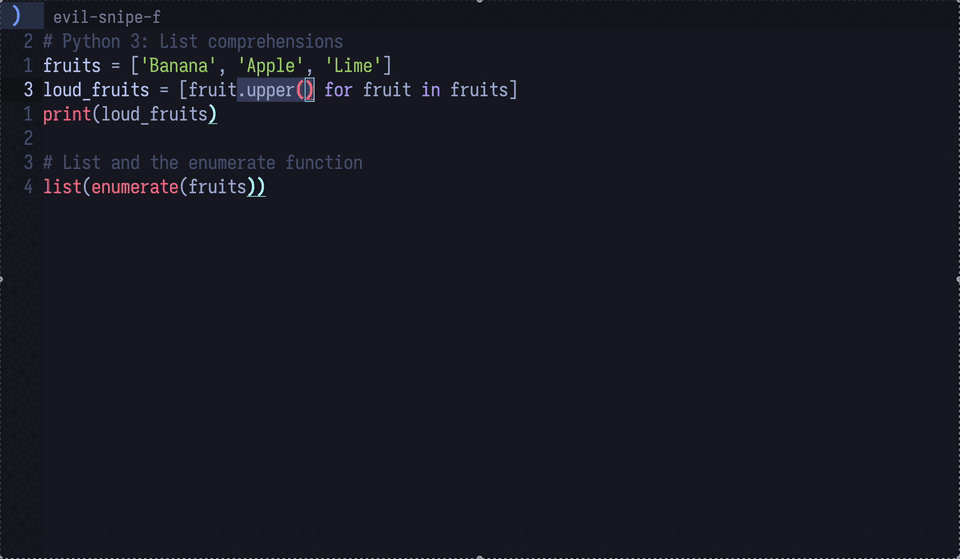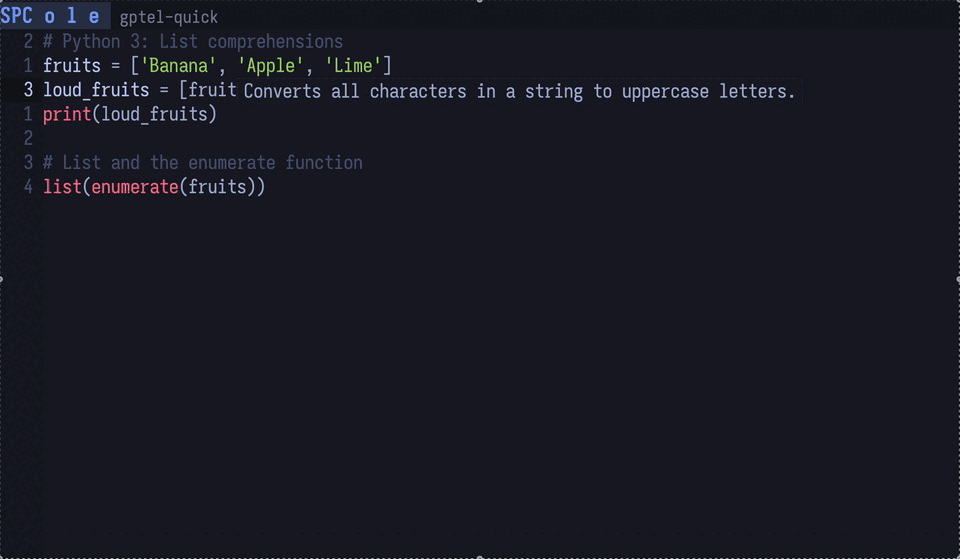
図4: python のupperメソッドをLLMに説明させている。これは地味に便利
まとめ
最近は多くの人がClaude-Code や Cursor といったAgent系のツールを使っていると思います。 もちろん自分もClaude-Code や opencode を使用していますし、これらのツールの便利さは理解しています。 一方で、これらのツールが提供する 楽さ の裏にはいくつかの トレードオフ があることも事実です。 使っているうちにいつの間にか主導権をLLMに握られ、彼らの妄言に付き合わされた結果非常に複雑な実装になってしまい、結局自分で書いた方が早かったりすることも結構あったりします。 さらに、自律的なAI agent に多くを任せすることによる思考力の低下2や、プログラミングの楽しさの喪失3などが懸念されたりもしています。
gptel は、LLMが提供する機能を最大限に活用しつつ、良い距離感を保ってくれる非常に謙虚なツールであり、これらの問題を回避するのにもってこいです。
タスクに応じたLLMクライアントの使い分けをするうえで、 gptel という選択肢は有力なものの一つだと思うので、まだ使ったことがない方はぜひ試してみてください。
おまけ: どの backend を使うか
gptel の README を見れば分かるように、gptel ではかなり多くの LLM の backend を使うことができます。
目的や使用量、予算によって選ぶべき backend は変わるのですが、 自分は Github Copilot Pro ($100.00 per year) に契約して、Github Models をメインの backend として使っており、今のところ満足しています。
Github Models backend を使っている理由
- AI 自動補完 のために pro plan を既に買っていたので追加コストがゼロだった
- 従量課金ではなく、定額制だから、コストを気にせず使える
- openai7種、Gemini 2種、Claude 3種の計12種類のモデルが使える4 (2025年6月現在)
-
コンテクストエンジニアリング: LLMに情報とツールを適切な形式、適切なタイミングで提供すること (参考記事)。これはエンジニアリングではないという意見もあるが、他に良い名前が無いので本稿ではこの用語を使う。 ↩︎
-
このブログ記事 に書かれている、AIがもたらす生産性向上とそれに伴う開発者の心理的・創造的満足度の低下という二律背反についての考察は非常に興味深いです。 ↩︎
-
Pro PlanではGPT-4.1/4oが無制限、その他モデルはモデル毎の倍率に応じて月300リクエストまで利用可能です(例: Claude Sonnet 3.7は1倍、GPT-4.5は50倍)。私はGPT-4.5 や Claude Opus 4 をほぼ使っていないからか、300回のプレミアムリクエストは思っていたよりも余裕がある印象です。 ↩︎