Introduction
The integration of large language models (LLMs) into Emacs has rapidly evolved over the past few years.
My first encounter with an LLM inside Emacs was in November 2022, through AI-powered code completion with copilot.el. I still vividly remember how impressed I was at that moment.
Shortly after, ChatGPT was launched, and tools like ChatGPT.el made it possible to interact with AI within Emacs—though, at that time, the features were few, and I didn’t really feel the advantages of using LLMs in Emacs.
A breakthrough moment for me was discovering ellama through Tomoya’s presentation at the Tokyo Emacs Study Group Summer Festival 2024. Unlike traditional conversational interfaces, ellama lets users leverage LLMs through various functions, transforming Emacs into a vastly more powerful development environment.
Recently, gptel was officially integrated as a llm module in Doom Emacs, making tool integration and prompt/context engineering1 significantly smoother.
By combining this with mcp.el, I feel that LLMs in Emacs have now reached a certain kind of plateau. If there are any fellow Emacs users (“Emacsers”) out there who still don’t know about this, it would be a real shame—so I’ve decided to write this article.
I will introduce how to set up gptel and mcp.el, explain why you should use them, and share some practical use cases.
gantt
title My Emacs LLM History
todayMarker off
dateFormat YYYY-MM
axisFormat %Y-%m
section Autocompletion
copilot.el :2022-11, 32M
section Dawn
ChatGPT.el :2023-03, 17M
org-ai :2023-12, 8M
section Revolution
ellama/llm :2024-08, 9M
section Pioneering
ai-org-chat :2024-11, 2M
ob-llm :2025-01, 2M
elisa :2025-03, 1M
copilot-chat.el :2025-03, 2M
section Maturity
gptel+mcp.el :2025-05, 2M
claude-code.el :2025-06, 1M
- copilot-emacs/copilot.el: An unofficial Copilot plugin for Emacs.
- joshcho/ChatGPT.el: ChatGPT in Emacs
- rksm/org-ai: Emacs as your personal AI assistant
- s-kostyaev/ellama: Ellama is a tool for interacting with large language models from Emacs.
- ahyatt/llm: A package abstracting llm capabilities for emacs.
- ultronozm/ai-org-chat.el
- jiyans/ob-llm
- s-kostyaev/elisa: ELISA (Emacs Lisp Information System Assistant) is a system designed to provide informative answers to user queries by leveraging a Retrieval Augmented Generation (RAG) approach.
- chep/copilot-chat.el: Chat with Github copilot in Emacs !
- karthink/gptel: A simple LLM client for Emacs
- lizqwerscott/mcp.el: An Mcp client inside Emacs
- stevemolitor/claude-code.el: Claude Code Emacs integration
What is gptel?
gptel is a simple yet powerful LLM client for Emacs, allowing you to interact with LLMs anywhere in Emacs, using formats of your choice. This demo gives a good image of what using it feels like.
What is mcp.el?
mcp.el is a package that brings the open protocol “Model Context Protocol (MCP)"—which standardizes AI and external tool integration—into Emacs. This allows LLM clients like gptel to communicate seamlessly with MCP servers that support a range of functionalities, such as web search, file access, and GitHub repository operations, greatly expanding the capabilities of your LLM. mcp.el acts as a hub, centralized within Emacs, for starting up and managing these external MCP services.
My gptel Settings
(use-package! gptel
:config
(require 'gptel-integrations)
(require 'gptel-org)
(setq gptel-model 'gpt-4.1
gptel-default-mode 'org-mode
gptel-use-curl t
gptel-use-tools t
gptel-confirm-tool-calls 'always
gptel-include-tool-results 'auto
gptel--system-message (concat gptel--system-message " Make sure to use Japanese language.")
gptel-backend (gptel-make-gh-copilot "Copilot" :stream t))
(gptel-make-xai "Grok" :key "your-api-key" :stream t)
(gptel-make-deepseek "DeepSeek" :key "your-api-key" :stream t))
mcp.el Settings Example
(use-package! mcp
:after gptel
:custom
(mcp-hub-servers
`(("github" . (:command "docker"
:args ("run" "-i" "--rm"
"-e" "GITHUB_PERSONAL_ACCESS_TOKEN"
"ghcr.io/github/github-mcp-server")
:env (:GITHUB_PERSONAL_ACCESS_TOKEN ,(get-sops-secret-value "gh_pat_mcp"))))
("duckduckgo" . (:command "uvx" :args ("duckduckgo-mcp-server")))
("nixos" . (:command "uvx" :args ("mcp-nixos")))
("fetch" . (:command "uvx" :args ("mcp-server-fetch")))
("filesystem" . (:command "npx" :args ("-y" "@modelcontextprotocol/server-filesystem" ,(getenv "HOME"))))
("sequential-thinking" . (:command "npx" :args ("-y" "@modelcontextprotocol/server-sequential-thinking")))
("context7" . (:command "npx" :args ("-y" "@upstash/context7-mcp") :env (:DEFAULT_MINIMUM_TOKENS "6000")))))
:config (require 'mcp-hub)
:hook (after-init . mcp-hub-start-all-server))
(Supplement)
There was an error where the mcp server, which is launched with uvx, could not start on NixOS.
I have written about the cause and solution for this issue in a separate article, so if you encounter the same error, please refer to that article.
Why I Use gptel (+mcp.el)
Here is your translation:
The reasons I use gptel & mcp.el can be summed up in the following three points:
- They are incorporated as modules in Doom Emacs, and can be used comfortably with almost no customization.
- You can freely use LLMs in any Emacs buffer.
- You have extremely high control over LLMs.
Points 1 and 2 are as explained above, but point 3 might require a bit of elaboration.
When it comes to using LLMs, I believe there are mainly three things we can control:
- The model (OpenAI GPT-4.1, Claude Sonnet 4, DeepSeek r1, etc.)
- Tools (web search, file access, etc.)
- Context (system messages, content of previous conversations)
To improve the accuracy of LLMs, properly controlling not just the model and tools, but especially the context is extremely important.
For example, it is known that LLMs can get fixated on their previous answers, or that their accuracy can decrease as the context grows longer. (In this article, this phenomenon is referred to as the AI Cliff.)
Recently, the term “context engineering” has become popular, but gptel has had features allowing easy context engineering long before the term existed.
Though I’ll introduce several use cases below, with gptel you can effortlessly switch models and tools, edit past conversation content, or branch the context.
I’ve tried various LLM clients, but I’ve never encountered another that makes it so easy to control all three key aspects of LLM usage.
Use Cases
For basic usage, the best way to learn is to watch the screen recordings in the gptel README or check out the official YouTube channel. If you prefer Japanese, this blog post explains things very clearly: gptel: A Simple LLM Client Running on Emacs is Extremely Convenient | DevelopersIO.
Since it wouldn’t be meaningful to just repeat what’s already covered in these two sources, I’ll focus here on a few use cases I personally like, specifically those not explained in detail above.
Switching Between Multiple Models Within a Single Session
Sessions in dialog format take place in plain text (org/markdown) buffers. For example, you can quickly and easily ask a question using a local LLM or a low-cost model first, and if the answer isn’t satisfactory, switch to a different model and send your request again.
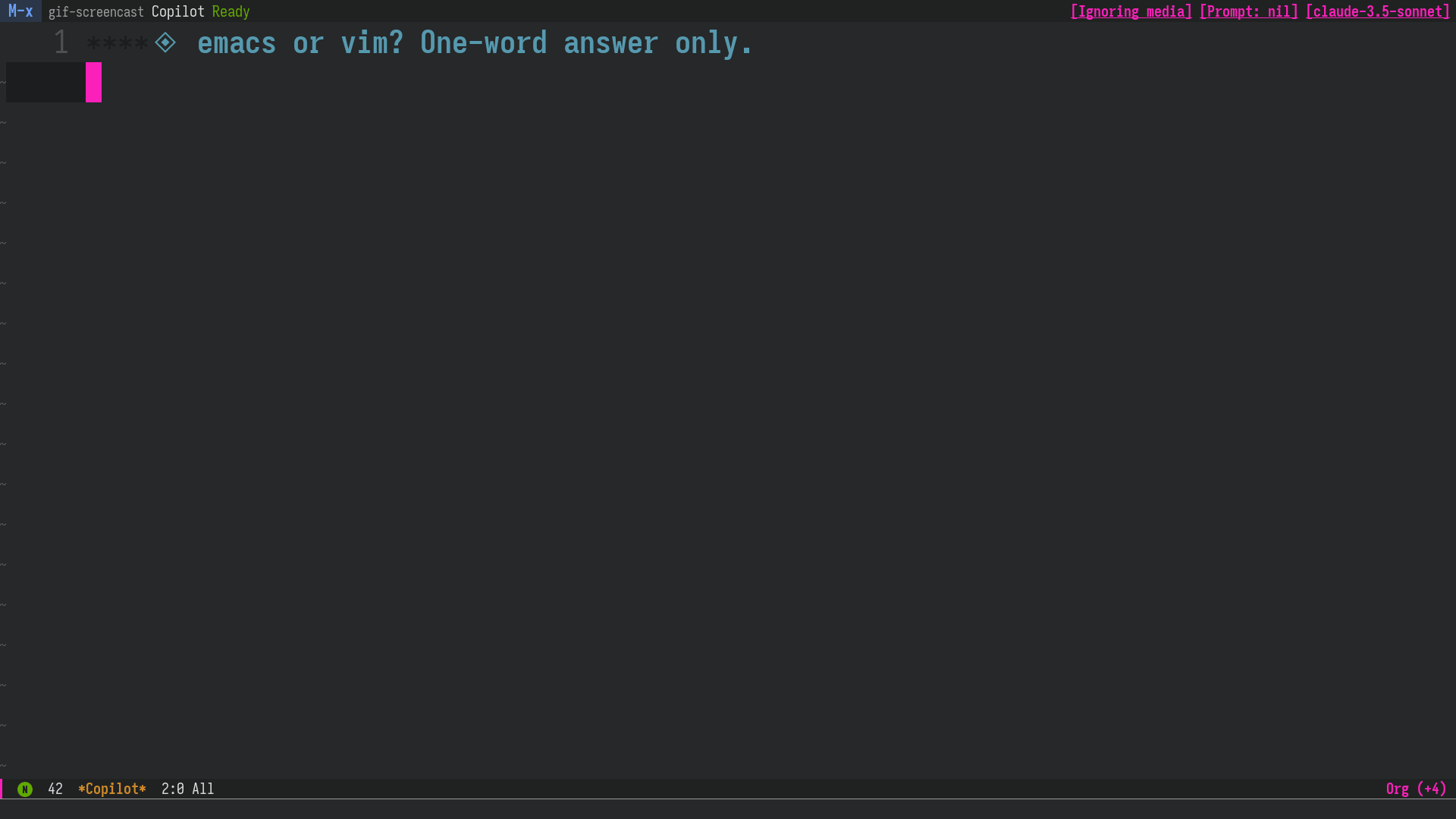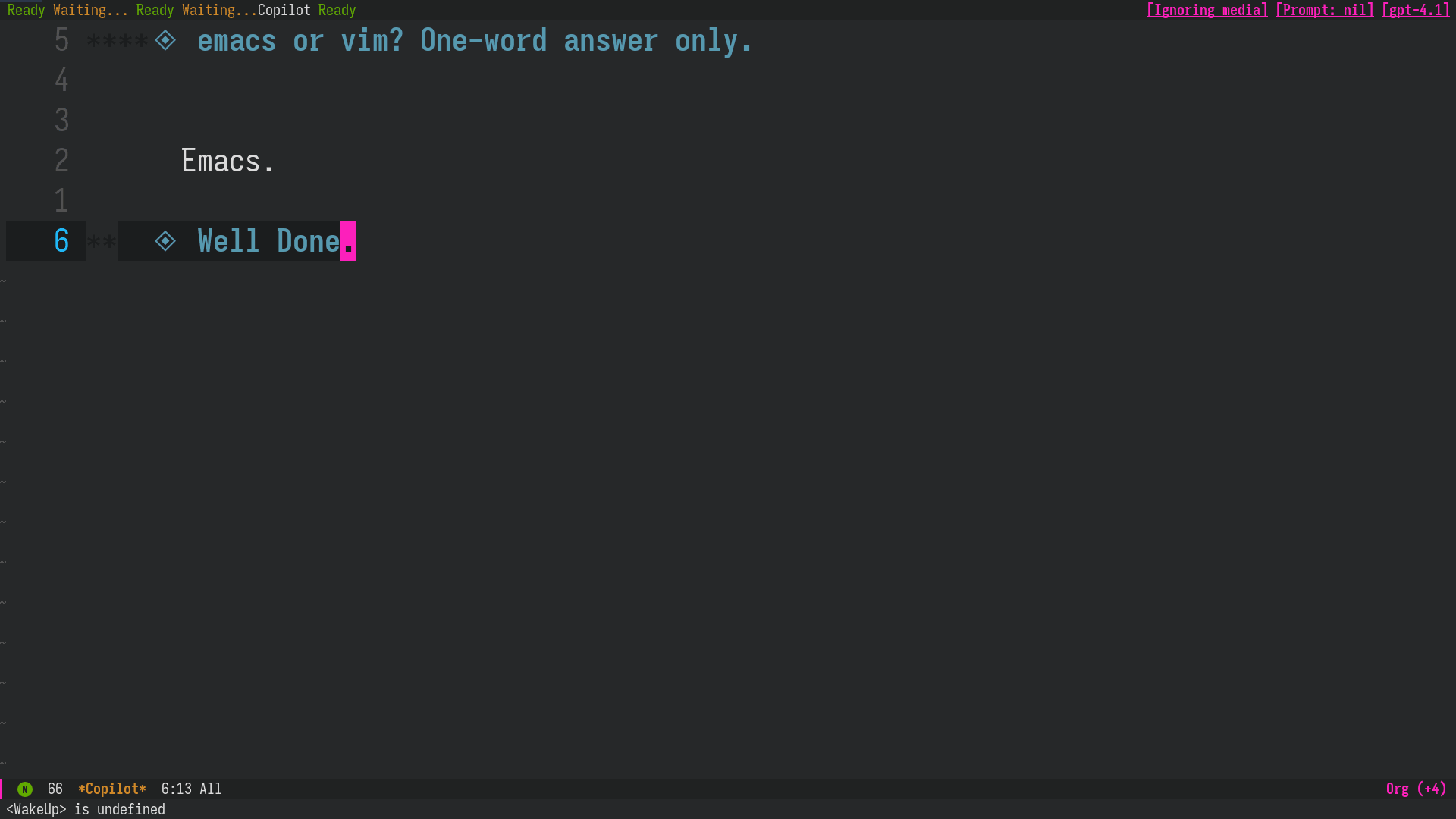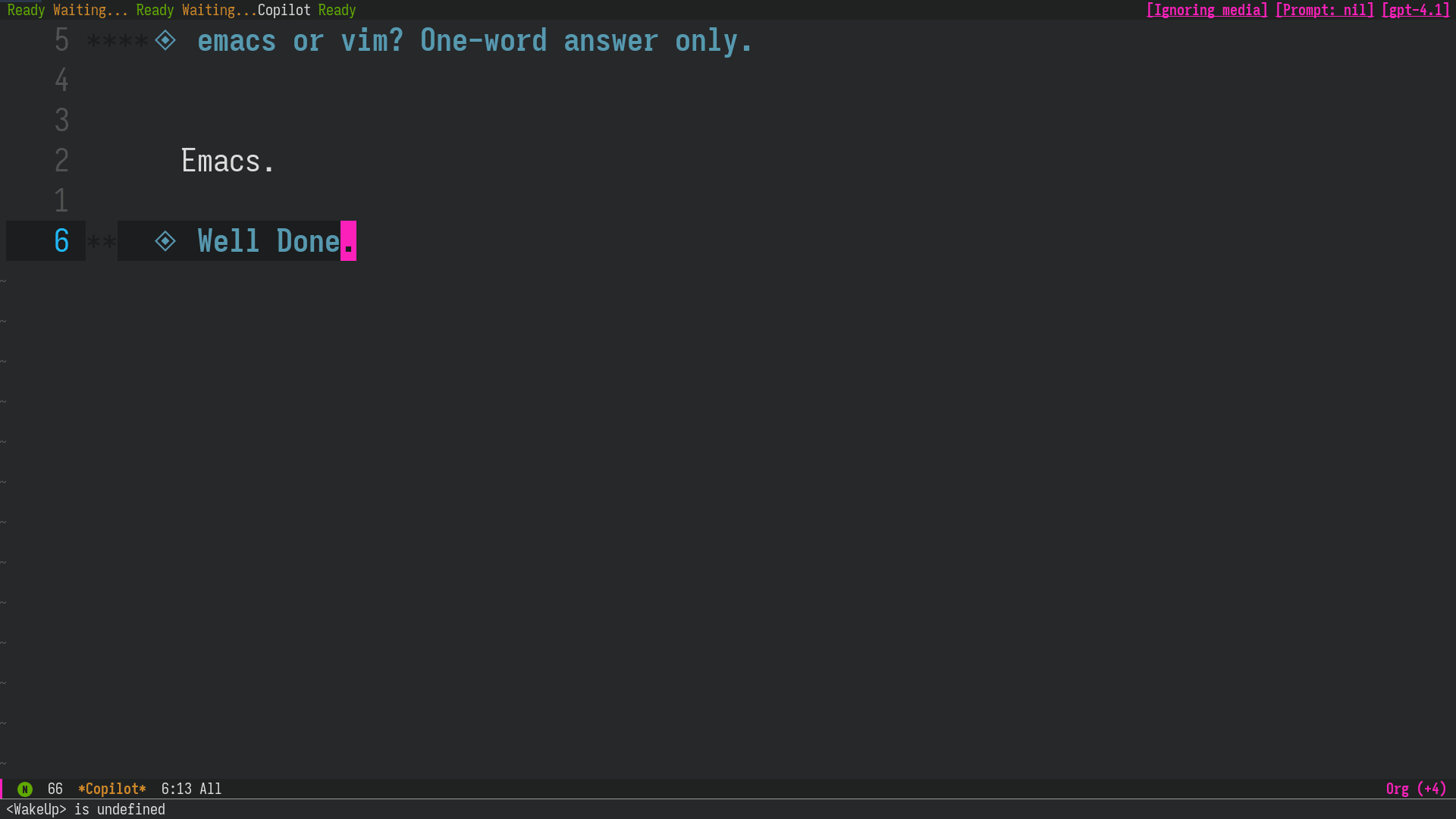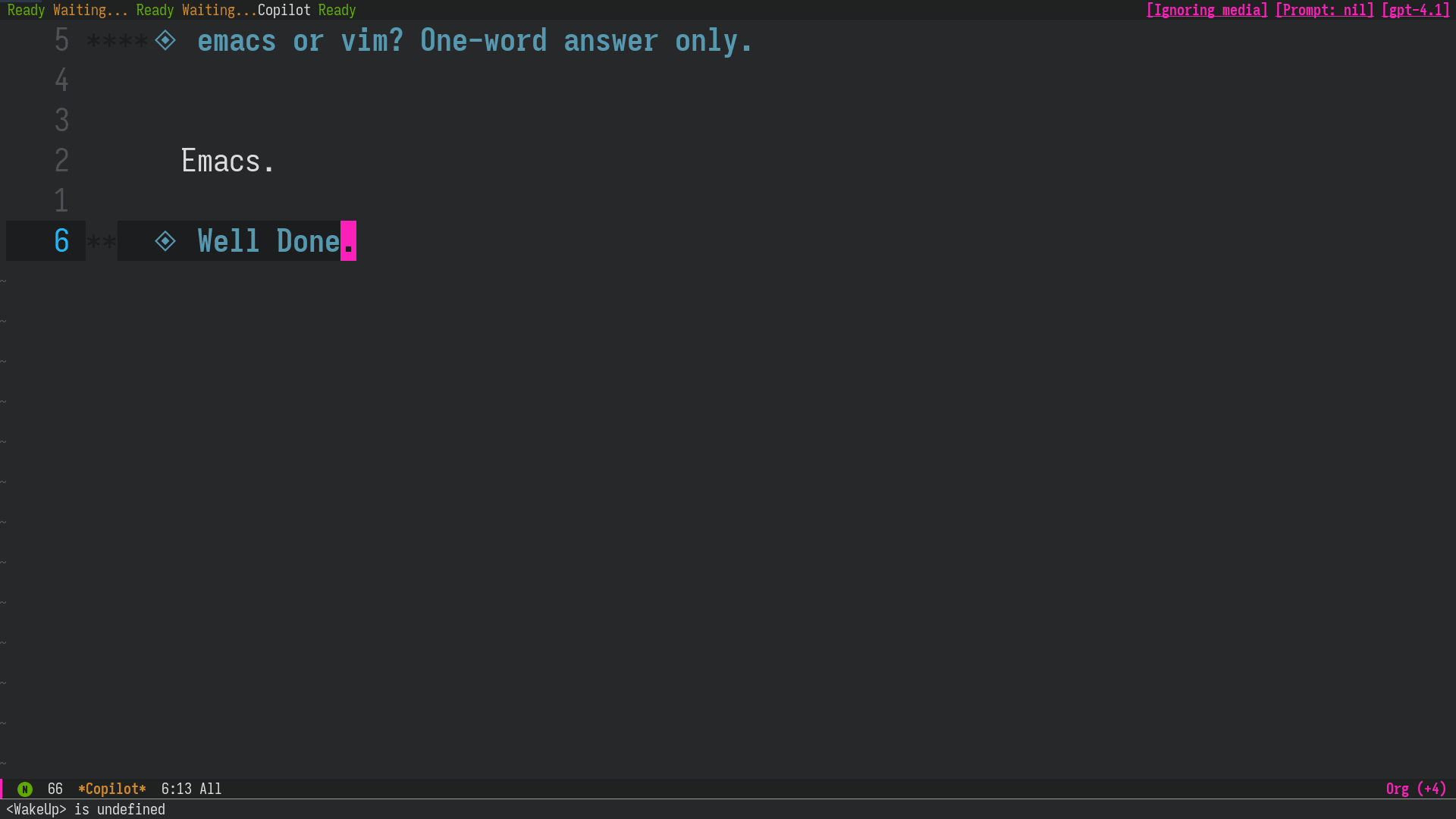
Figure 1: Usage Example: After Claude Sonnet gives an incorrect answer, switch to GPT-4.1 and ask the question again
Editing LLM Responses
It’s also possible to delete or edit the LLM’s previous responses before asking another question, making it simple to guide the flow of conversation. This helps suppress what I referred to in the previous section as the AI Cliff.
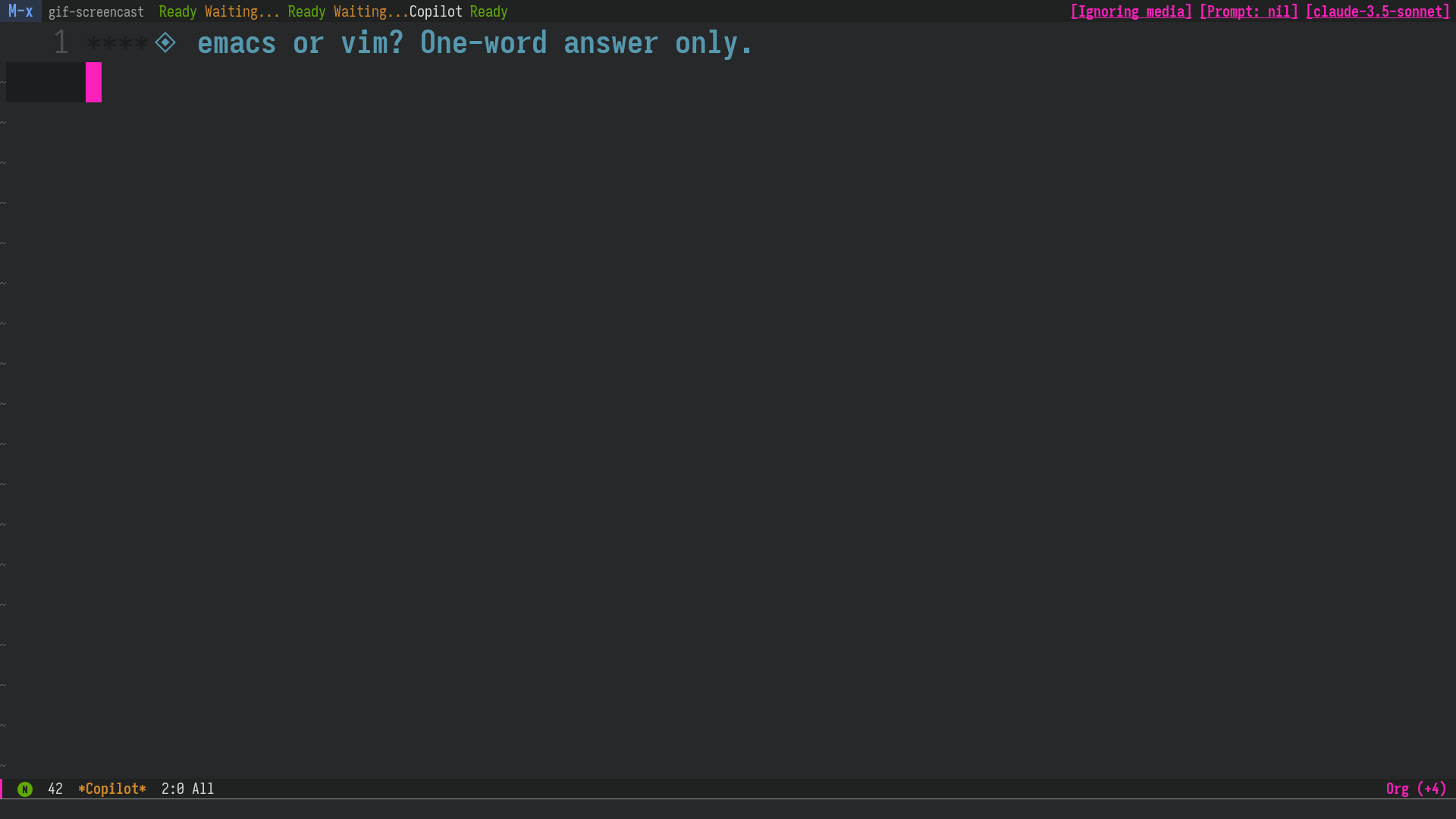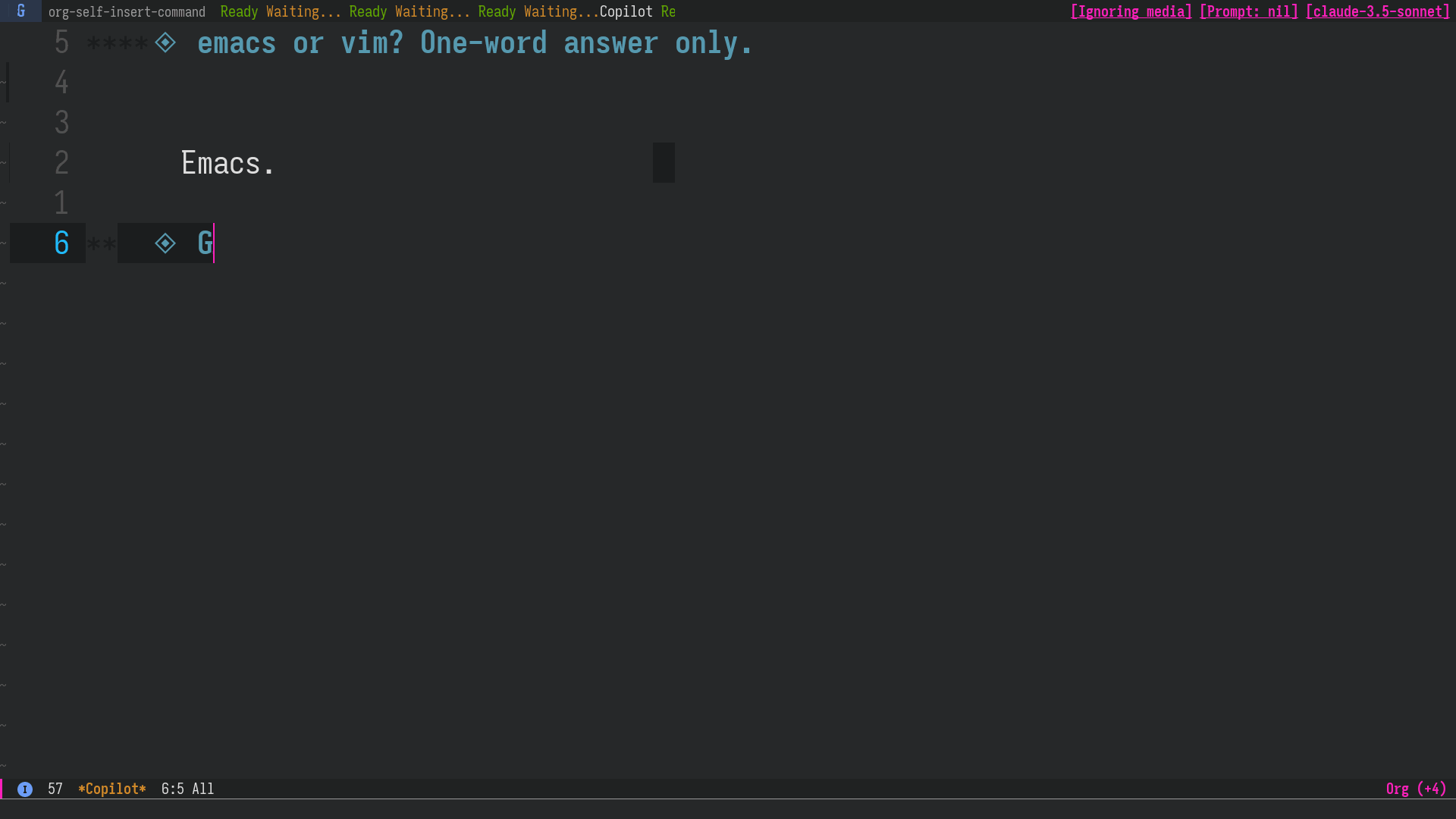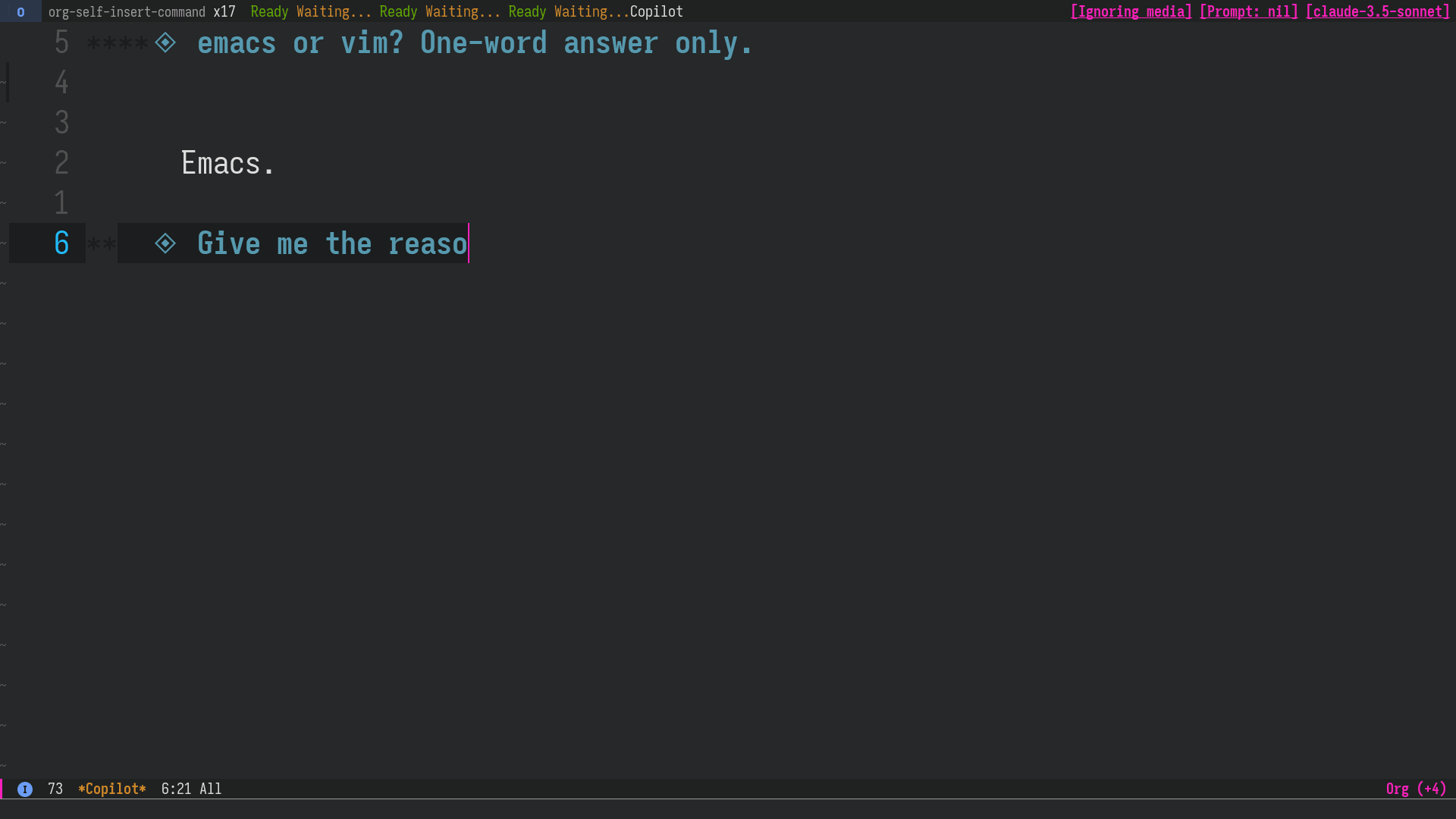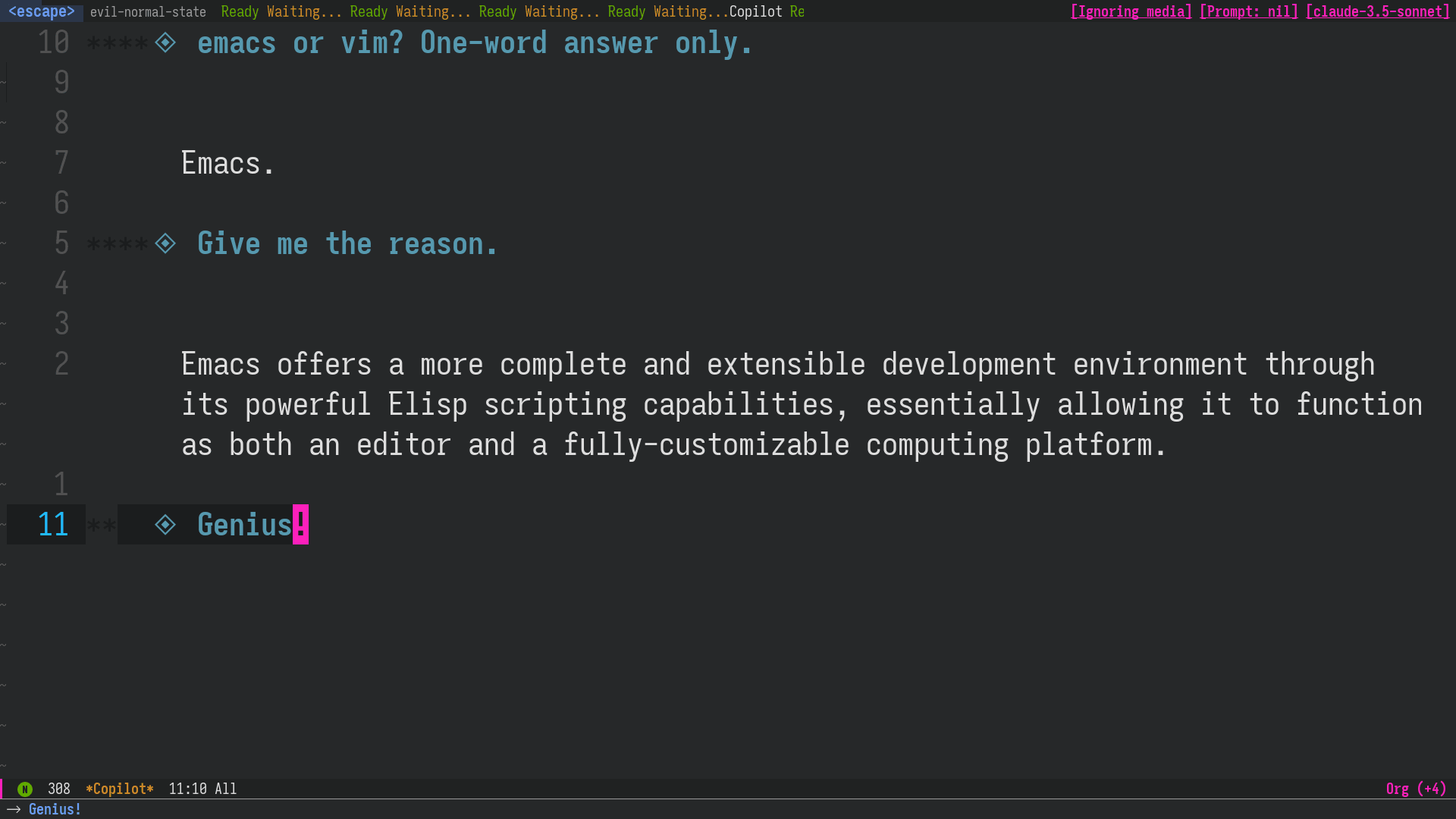
Figure 2: After correcting an incorrect answer from Claude Sonnet, continue the conversation as if the LLM had answered correctly
Topic Restriction Feature
The command M-x gptel-org-set-topic lets you set properties in the header to restrict the context for each section.

Figure 3: LLMs now pick up on subtle cues. Apply topic restriction to get unbiased responses.
Context Branching
To structure context restriction even further, there is the gptel-org-branching-context feature.
For example, if you want to inquire about a specific document, you can copy and paste that document into the top-level header, write independent questions under lower-level headers, and get separate answers for each question, using the content of the document as context.
* 1st level heading
<Content you want included in global context>
** 2nd level heading 1
Question 1
@assistant
<llm response>
*** 3rd level heading
<Follow-up question related to question 1>
@assistant
<llm response>
** 2nd level heading 2
Question 2
The context sent to the LLM here will not include the content of question 1; only <global context> and question 2 will be sent.
To use this feature, you need to enable gptel-org-branching-context as shown below.
# Local Variables:
# gptel-org-branching-context: t
# End:
Obtaining Information from Hovered Sections
By using the gptel-quick function provided by gptel, you can query the LLM about information at your cursor position.
It’s like having “hover & describe” of LSP available everywhere.
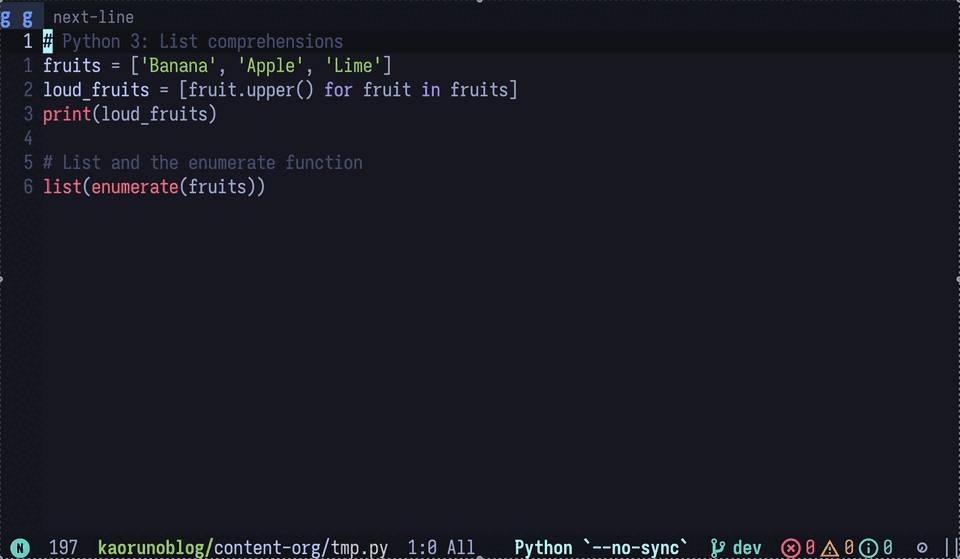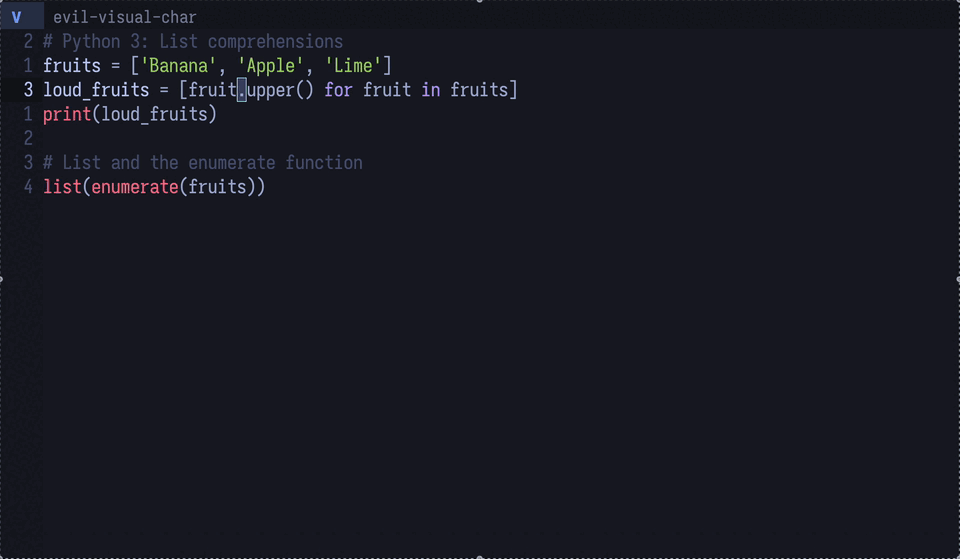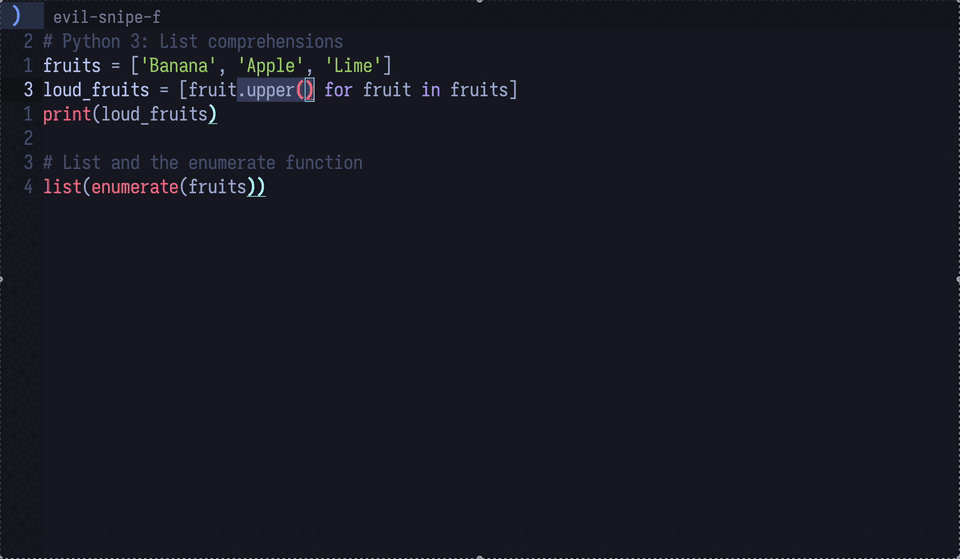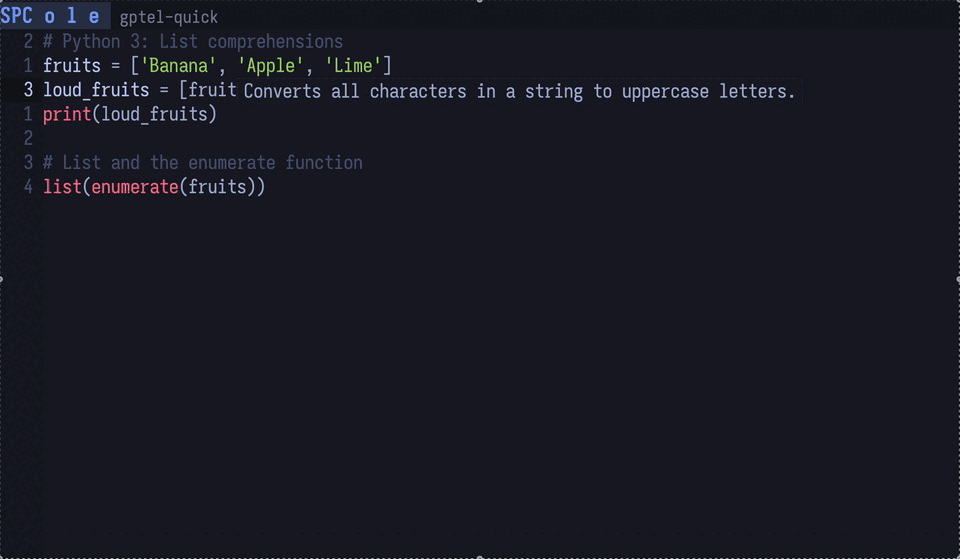
Figure 4: The LLM is asked to explain Python’s upper method—a feature that’s surprisingly handy
*/ Summary Lately, many people are using agent-oriented tools like Claude-Code and Cursor. Of course, I use Claude-Code and opencode myself, and I understand how convenient these tools are. However, it’s also true that the ease these tools provide comes with a few tradeoffs. As you use them, you may find you’ve inadvertently handed control over to the LLM, followed its rambling suggestions, and ended up with a far more complex implementation—sometimes it would’ve been faster just to write it yourself. There are also concerns about diminished thinking ability2 when leaving too much to autonomous AI agents, and even about losing the enjoyment of programming3.
gptel is a humble tool that maintains a good distance while maximally leveraging LLM capabilities, making it perfect for sidestepping these issues.
As you choose which LLM client to use for each task, I think gptel is an outstanding option. If you haven’t used it yet, I highly recommend giving it a try!
Which Backend to Use
As you can see from the gptel README, gptel supports a wide variety of LLM backends.
Depending on your needs, usage, and budget, your backend choice may vary. Personally, I have a subscription to Github Copilot Pro ($100.00/year), and I mainly use the Github Models backend—which has been satisfactory so far.
Why Do I Use the Github Models Backend?
- I was already paying for a Pro plan for AI autocompletion, so there was no additional cost.
- Instead of pay-as-you-go, it’s a flat fee—so I don’t have to worry about cost.
- There are 12 different models available (as of June 2025): 7 from OpenAI, 2 Gemini, and 3 Claude models4.
-
Context Engineering: Providing LLMs with the right information and tools in the right format at the right time (reference article). ↩︎
-
The claim in this paper, though slightly different in context, applies equally from the AI agent’s perspective. ↩︎
-
The reflections in this blog post about the productivity gains and diminishing psychological/creative satisfaction for developers brought by AI are extremely thought-provoking. ↩︎
-
On the Pro Plan, GPT-4.1/4o are unlimited, and the other models can be used up to 300 times per month (with multipliers per model; e.g., Claude Sonnet 3.7 is 1x, GPT-4.5 is 50x). Since I rarely use GPT-4.5 or Claude Opus 4, I find I have more room in those 300 premium requests than expected. ↩︎