
図1: 二十七の僕には誰にも話せない悩みの種があるのです
はじめに: AIは専門家を不要にするという風潮の問題
ここ数年、専門的なホワイトカラーの仕事がAIに奪われるという話を至る所で耳にします。
私自身学部時代から、仕事でも研究でも趣味でもデータサイエンス(以下、DS)にどっぷり浸かってきたのですが、 最近ではテクノロジーに疎い家族やプログラミング経験のない友人から、「まだプログラミングやってるの?」「AIで全部できるんじゃない?」と、悪気なく言われるようになりました。
こうした声は身内だけにとどまりません。 驚くべきことに、名だたる大企業のマネージャーレベルの人や、コンサルティング業界で長年活躍されてきたような、いわゆるエリートの方々からも、
『DS領域でやっていこうとするのは勧めない』
『データサイエンティストが一番最初にAI に代替される職業なのではないか』
と言われてしまいました。

図2: それ、本当?
つい先日も、知り合いの優秀な大学院生が「データサイエンティストの将来は暗い」という周囲の声に惑わされ、大学院を中退しようと真剣に悩んでいました。
私は、 データサイエンティストの仕事を完全にAIで置き換える未来が数年以内に来る可能性は極めて低い と考えており、AIへの過度な期待が企業の判断を誤らせたり、「AIがなんでもやってくれるから自分は何も学ぶ必要がない」という極端な考えが若干広まりつつある現状に強い危機感を覚えています。
この状況に対し、データ分析をしている側の人間として立場を明確に示す責任があると感じ、「データサイエンティストがAIに代替される」論者の主張としてよく見られる以下の意見:
のひとつひとつに対し、現場の者を(勝手に)レペゼン1してアンサーしていこうと思います2。

図3: I’m not a rapper
現状のLLMの課題
AI は コードを書けるから、データサイエンティストは不要になる
これは、第一線で活躍されているコンサルの方から実際に私が言われたことです。
たしかにここ数年、特にコーディングの分野でのAIによる変化は凄まじく、そう思うのも無理はありません。 Tomlinson et al. (2025)が算出しているAI Applicability scores 3では"Data Scientist"はトップ30に入っており4、DSの業務と生成AIとの親和性が非常に高いことを示しています。 過去ブログにも書きましたが、私自身も2022年の終わり頃から生成AIを使っており、コーディングやリサーチ、資料作成や勉強など、様々な場面で恩恵を受けています。
しかしこの「生成AIの登場でデータサイエンティストが不要になる」という考えは電動ノコギリの登場が大工を不要にする と言うのと同じくらい 的外れ なことだと思います。
(前提) “データサイエンティストの仕事=コーディング” ではない
組織やポジションによって様々ですが、一般的にデータサイエンティストと呼ばれる仕事には上の資料にあるような多様な役割が含まれます。 そのため、LLM がコーディング作業を代替したとしてもデータサイエンティストの仕事がなくなるわけではありません。 自分でコードを書く時間が減り、課題設定や分析設計、実装の監督と検証、ステークホルダーとのコミュニケーションなどの 付加価値が高いタスクにより多くの時間が割かれるような形に転換されていくだけ というのが現実的なシナリオだと思います。 (ていうか、多くの仕事で既にこの類の変化は始まっていると思いますが。)
生成AIによるコーディングの限界とリスク
生成AIのコーディング能力に対する感覚のギャップも、普段コーディングをされない方々との間で感じます。 おそらく、AIエージェントのようなツールを使いこなせば、データ分析を含む多くの高度なタスクを、誰もが簡単に行えるようになると捉えられているのではないでしょうか。
しかし、AIにコーディングを任せることには、その能力的な「限界」と、生成されるコードがもたらす「リスク」という、看過できない2つの側面が存在します。
単純作業は得意だが複雑なタスクは苦手
たしかに、ちょっとした集計やプロットなど、単純なタスク・使い捨てのコードは、AIで十分なことも多いです。 実際私もClaude Codeやopencodeを使って自分で一行もコードを書かずに数分でいくつか簡単なツールを作成し、問題なく使うことができています。
しかし、 複数のステップを踏むタスクや、長期的に運用する必要があるコードは、AIに任せるというのはほぼ不可能 なのが現実です。
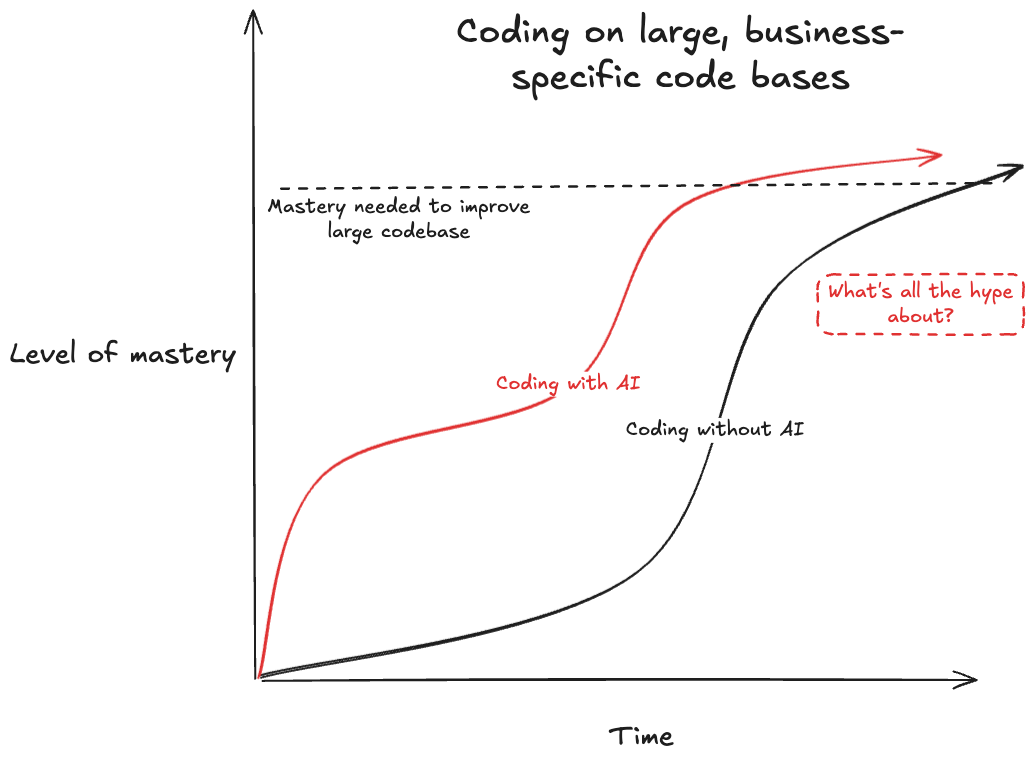
METRのリサーチ が示すように、AIはコーディングベンチマークでは優れたパフォーマンスを発揮しているように見えても、実際のプロジェクトでは人間のパフォーマンスに遠く及びません。
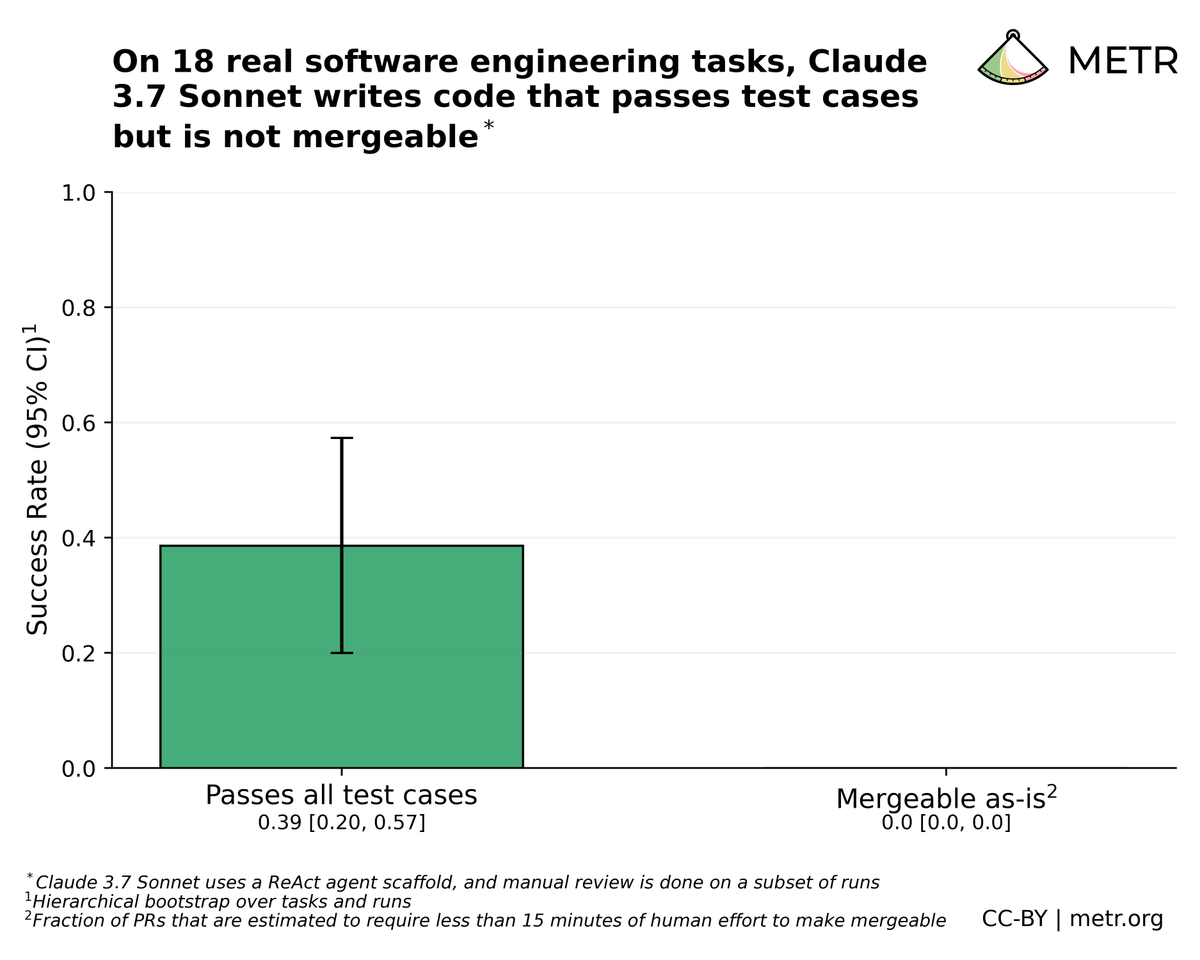
LLMのベンチマークが実務に対して過大評価になる一つの可能性として、モデルがRLVR(Reinforcement Learning with Verifiable Rewards)で訓練されている点が挙げられています。 RLVRで訓練されたモデルは、テストのような「検証可能」タスクに特化し、ドキュメント、コード品質、可読性、保守性などの、検証は困難だが実務では重要な側面については弱い傾向にあります。
そしてデータ分析はこのテストによる検証可能性という点でLLMとの相性が良くありません。 なぜなら、データ分析ではアウトプットに「唯一の正解」が存在せず、一般的なソフトウェアのUI/UXやAPIのように「正常な見た目・動作」に基づいたテストを作るのが難しいからです。
「勝ちに不思議の勝ちあり、負けに不思議の負けなし」って言うように、統計分析は正しい分析はないけど、ダメな分析はある。
— Ken McAlinn (@kenmcalinn) July 27, 2025
AIは、もっともらしいグラフや統計量を生成することはできるかもしれません。 しかし、その分析プロセスに潜む交絡因子や選択バイアス、data leakageといった「ダメな分析」の兆候を見抜き、ビジネスの文脈に照らして結論が妥当であるかを判断することは極めて苦手です。 分析結果が「一見正しく見える」ことと、それが「本当に信頼できる」ことの間には、大きな隔たりがあるのです。
よってLLMのコードをベースに妥当な分析をするには、 結局人間の徹底的なレビューが必要になります 5。
ここで、
そのレビューもAIにさせれば良いではないか
という反論がありそうですが、LLMどうしの相互レビューには、いくつかの問題があります。
第一に、LLMは手本となる少数の例から学習する際、自身の誤った予測と正しい答えを一緒に提示して修正を試みても、かえってタスクの理解を妨げ、性能を低下させてしまうことが示されており(Sanz-Guerrero and von der Wense 2025)、その自己修正能力には限界があると考えられます。 実際、人間によるレビューコメントの60%がコード変更につながったのに対し、LLMによるレビューコメントは0.9%〜19.2%にとどまったという研究結果もあります(Sun et al. 2025)。
この点は今後改善されるかもしれませんが、致命的なのが後ろのセクションでも述べているコンテクストの問題です。 優れたコードレビューとは、単なるバグチェックではありません。 そのコードがビジネス上の目的や全体の設計思想に合致しているか、長期的な保守性まで考慮されているか、といった深いコンテキストの理解が不可欠です。 AIにはこの背景知識に基づいたレビュー能力が決定的に欠けているため、表面的なレビューしかできません。 人間が徹底的にコンテクストを管理することで対応を試みることはできますが、そんなことするくらいだったら最初から人間がレビューした方が早いでしょう。
保守性の低いコードとセキュリティリスク
そして、エンジニアリングにおけるLLMの副作用は看過できないものとなっています。
Cursor や Claude-Codeのようなエージェント系のエディタでは、ユーザーが特に頭を使わなくてもどんどんコードが生成されます。 もちろん生成されたコードをひとつひとつ確認するようにもできますが、人間は楽な方に流されるのが常です。 意図が分からないコードが増えていき、エラーのたびにAIがその場しのぎのパッチを繰り返し、最終的には増築を繰り返した違法建築物みたいなレガシーコードが出来上がります6。 このようなコードはもはや資産ではなく、負債です。 実際に、LLMへの過度な依存によるコード品質の低下やコストの増加やレビュワーの負担増大がいたるところで問題になっています。
このような保守性の低いコードは、それ自体がセキュリティ上の深刻な脆弱性となり得ます。 意図が不明瞭で複雑に絡み合ったコードは、バグやセキュリティホールを生み出しやすくするだけでなく、脆弱性の発見や修正を著しく困難にするからです。
さらに、AIエージェントにシステムへやインターネット、データベースへのアクセス権限を与えることは、新たな攻撃ベクトルを生み出します。 最先端のAIエージェントでもprompt injectionなどに対しての攻撃には極めて脆弱なことが知られており(Zou et al. 2025)、データベースの削除や改ざん7・機密情報の漏洩を防ぐには、やはり人間によるコントロールが必要になります8。
目先の効率化に目を奪われ、こうしたAIの限界とリスクに対する認識が甘いまま専門的な業務を丸投げすることは、単なるプロジェクトの失敗では済みません。 それは、 将来にわたって組織を蝕む「技術的負債」を抱え込み、修正困難なセキュリティリスクを常態化させ、結果として企業の競争力そのものを削いでいく極めて危険な賭け と言えるでしょう。
AIによる自動化までの壁は高い
AIはまだ発展途上だから、今は完璧じゃなくても、そのうち解決する
という意見もよく聞きます。 コーディングに限らず、課題設定や分析設計など、より上流のタスクもAIが自律的にこなせるようになる、という期待を持っている人も多いと思います。
仮にそうだとしても、 その未来はいつ来るのでしょうか?
今、 我々がAIに求めるタスクの難易度は指数関数的に上がっている 一方で、逆に LLMの指数関数的な進化については疑問視する声が増えており 、 AIの進化がDSの仕事を完全に自動化する未来が近いうちに来るかどうかは非常に不透明 というのが、私の見解です。
複数ステップのタスクの自動化は極めて難しい
現在のLLMが文章の要約や翻訳、コードの生成といったタスクで見せる能力は、確かに目を見張るものがあります。 しかし、DSを含む多くの仕事のように、複数のステップからなる複雑なプロセスをAIで代替させるとなると、話は少し違ってきます。 プロセス全体のエラー率は、ステップを重ねるごとに指数関数的に増幅されるからです。

図6: 仮にそれぞれ単一のタスクの成功率が95%(これは現在のLLMにとってはかなり楽観的な数値)だとしても、20のステップを経た最終的な成功率は36%にまで低下する
そして、その過程には「罠」が数多く存在します。 データ分析の現場は、機械的な手順で手を動かせばよい部分は少なく、常に予期せぬ問題やデータの落とし穴に対処しなければなりません。
残念ながら、こうした「罠」を回避するために人間が普段使っているような能力が、 LLMには根本的に欠けている ことが指摘されています。 例えば、データ分析では「手元にあるデータだけでは不十分」あるいは「~のような追加のデータや情報が必要だ」と判断することがありますが、LLMは 「欠けているもの」を認識するのが非常に苦手 です(Fu et al. 2025)。 それどころか、重要なコンテキストが欠けているにもかかわらず、 手元のデータのみで直接回答を試み、結果としてパフォーマンスが著しく低下する 傾向があることも指摘されています(Shen 2025)。
ChatGPT-5 recommended a nail place with mani and pedi for $25-$30 - seemed too good to be true.
— Xiao Ma (@infoxiao) August 11, 2025
I followed the link. The source? A 2016 article quoting those prices.
That got me thinking: an intelligent person would look at the date and be like "Wow, that's 10 years ago.…
また、「罠」を回避するためには、結果を批判的に吟味するために論理的思考力を必要とします。 一見、LLMが「思考の連鎖 (Chain-of-Thought)」によって論理的な推論を行っているように見えるかもしれませんが、その実態は 訓練データに存在するパターンを高度に模倣しているに過ぎず、真の論理的思考ではない ことが示唆されています(Zhao et al. 2025)
つまり、現在のLLMは未知の問題や、これまでに見たことのないようなデータの「罠」に対しては、 人間のように柔軟に対応することができない根本的な問題 を抱えているのです。
それ以外にも、ハルシネーション (Xu, Jain, and Kankanhalli 2025)など、現在のLLMには実務で使うには致命的な課題が山積みです。
理論上だけでなく、実際の職場環境を模したベンチマークでも、人間が行なっている業務への適応のハードルの高さは明らかです。 AIエージェントが複雑なオフィス業務を最後までやり遂げる成功率は、30〜35%程度に留まるという報告もあります(Xu et al. 2025)。
LLMの成長はプラトーを迎えた?: スケーリング則の限界
でも、それは今の話で、AIは指数関数的に進化しているのだからすぐに解決する
という反論が聞こえてきそうですが、その主張には確かな根拠があるのでしょうか?
近年のAIの目覚ましい進歩は、モデルのサイズと学習データをひたすら増やす スケーリング則 と呼ばれる力技によって支えられてきました。 しかし、このアプローチは物理的・経済的な限界にぶつかりdiminishing returns(収穫逓減)の兆候が明確に現れ始めています(Coveney and Succi 2025)。 モデルを大きくすればするほど性能向上の幅は小さくなる一方で、学習に必要な計算資源とコストは天文学的に増大し続けています。
この状況に対し、多くの研究者が警鐘を鳴らしており、AIの進歩が停滞期(プラトー)に入りつつあるという認識が広まっています。 最近のAAAIの調査では、AI研究者の大多数が、 スケーリング則だけではAGI(汎用人工知能)には到達できない と考えていることが示されました。 業界を牽引するトップの研究者たちですら、現在の延長線上にAGIはないと考えているのです。
これらの課題が、そう遠くない未来に解決されることを願っていますが、 この現状を見てもなお、AIがデータサイエンティストを含む専門的な知識を要するホワイトカラーの仕事を完全に代替できると本気で信じているのだとしたら、それは少し楽観的すぎるのではないでしょうか?
LLMの失敗は組織のノウハウとして蓄積されない
ここで、
LLMのハルシネーションは、結局のところ人間のヒューマンエラーのようなものではないか?
人間も間違うのだから、許容すべきだ
という反論があるかもしれません。
しかし、この二つは似て非なるものです。 最大の違いは、LLMは 「知らない」ということを知らず、事実無根の情報を自信満々に生成してしまう 点です。 人間であれば不確かな情報に留保をつけられますが、LLMは平然と嘘をつきます。 さらに、人間は失敗から学習することができますが、
さらに決定的な違いは、 学習能力の有無 です。
人間は失敗から学び、同じ間違いを繰り返さないように経験を次に活かしますが、LLMにはその能力がありません(前向性健忘に似ている)。
LLMは間違いを指摘されても、そのセッションが終わればすべて忘れてしまうからです。
仮に AGENTS.md みたいなファイルに毎回記憶するようにしても、コンテクストウィンドウの物理的限界、直近バイアス (Zhao et al. 2021)、コンテクスト腐敗 (Hong, Troynikov, and Huber 2025)などの問題に直面し、根本的な解決にはなりません。
つまり、人間が自然にやっている「一度犯したミスを二度と繰り返さないよう成長する」ことがLLMにはできないのです。
この点を踏まえると、 ブラックボックスから出てきた分析結果を受け入れるだけの「AIおみくじ」状態にしてしまうことは、経営の観点から見ると極めて危険です。 なぜなら、 AIによる試行錯誤のプロセスは、組織の知的資産として全く蓄積されない からです。 人間のデータサイエンティストが苦労して得た知見は、次のプロジェクトに活かされる「ノウハウ」となりますが、AIのエラーは単に消えていくだけのコストです。 目先の効率化のためにAIに丸投げすることは、組織から学習の機会を奪い、長期的な競争力を削いでいく行為 に他なりません。
LLMの性能が上がっても、結局専門性のある人間の介入が必要
LLMの性能が上がっても、コンテクストがボトルネックになる
仮に、LLMが最新の統計学や機械学習理論を完璧に理解し、ビジネスへの実装までこなせるようになり、ノウハウ蓄積の問題もなんらかの方法で解決されたとします。
それでもなお、データサイエンティストの仕事が代替されないと考える大きな理由があります。 それは、どんなに優れたAIであっても、アウトプットの質はインプットされる 「コンテクスト」 に決定的に依存するからです。
経済学者アセモグルも言及しているように、 客観的な成功基準が曖昧で複雑なコンテクストに依存するタスクは既存の労働者に頼らざるを得ないため、完全な自動化が困難です。 成功基準が曖昧な点は先ほども指摘しましたが、データ分析はまさにこの「明確な成功基準を持たず、コンテクスト依存の変数が多いタスク」の典型です。
この事実は、実際のツールの使われ方にも表れています。 冒頭で紹介したCopilotのフィードバック分析(Tomlinson et al. 2025)では、「文書の執筆・編集」や「情報のリサーチ」といったタスクでユーザーは高い満足度を示している一方で、 「データ分析」に対する満足度は最も低い という結果が報告されています。 これは、AIがデータ分析というタスクを遂行する上で、決定的に重要な「何か」が欠けていることを示唆しています。
その「何か」こそが、コンテクストです。
現実のビジネス課題は、Kaggleのコンペティションのように、美しく整備されたデータセットと明確な評価指標が与えられた状態で始まるわけではありません。
- この分析はどのような目的で、誰に対して見せるものなのか?
- そのデータにバイアスはないか?
- 他にもっと良いデータは入手できないか?
- モデルの評価指標はそれで本当に適切か?
- 業界特有のドメイン知識や、現場だけで培われた経験則は何か?
こうした情報は、形式化されていない 「暗黙知」 です。AIのパフォーマンスを最大化するには、この膨大で雑多な暗黙知をすべて言語化し、コンテクストとして与えなければなりません。 しかし、その作業自体が、まさに専門性を持つ人間の仕事になってしまいます。 なぜなら、 無数の情報の中から「どの情報が課題解決に役立つか」を的確に判断し、AIに与えること自体が、高度な専門性を持つ人間にしかできない仕事 だからです。 そして、 それはまさしく、データサイエンティストがやってること、経験を積み重ねている仕事そのものです 。
つまり、AIが進化すればするほど、それを使いこなすための「コンテクストを正しく与える能力」が重要になります。 この能力は専門知識と経験に裏打ちされているため、データサイエンティストがAIを最も効果的に使えるのは明らかであり、企業がこの役割を素人に任せる選択をするメリットはほとんどありません。
AIがどれだけ進化しても残る懸念
AIがどれだけ進化しても、DSの仕事が完全に自動化された場合、いくつかの懸念が残ります。
責任の所在:AIの失敗を誰が償うのか?
AIの分析結果が超いいかげんなもので、それによって失敗したら、責任は、一体誰が負うのでしょうか? 多くのLLMサービスと同様に、「この分析は不正確な場合があります。中身は再確認してください。」みたいな免責事項でも付けるつもりでしょうか?
AIは、どのようなプロセスでその結論に至ったのかを説明する真似はできても、その結果に対して責任を取ることはできません。 責任の所在が曖昧なシステムに、企業は自社の命運を委ねるという選択を取るのか 疑問です。
恣意的な利用:AIは「都合の良い真実」を語る道具になるか?
この前、トランプ大統領が自らに不都合な雇用統計を発表した労働統計局長を解任したというニュースがありました。 これは、客観的なデータやそれを示す専門家が、時に権力者にとって邪魔な存在となり得ることを示す象徴的な事件です。
これは人間の場合でもしばしば起こることではありますが、AIへの代替によって 分析自体が恣意的に操作されるリスクの増加 が懸念されます。 独立した倫理観を持つ人間と異なり、AIはプロンプトやパラメータを調整しながら望む結果が得られるまで何度も繰り返すことができ、指示者にとって都合の良いアウトプットを出すようにコントロールすることが はるかに容易 です。 そうなれば、DSは客観的な意思決定を支えるものではなく、 「結論ありき」の主張を正当化するための都合の良い道具 に成り下がってしまいます。
専門性の価値は下がらない
AIで誰でも専門的な知識を得られるから、専門性の価値は下がるのでは?
これもまた、よく耳にする意見です。 たしかに LLMは学習ツールとして最高 です。 これを使えば、誰もが簡単に専門知識を身につけられるようになり、結果として専門家と非専門家の差は縮まる、という考え方でしょう。
しかしこの考え方には、 時間をかけて蓄積した知識と、生成AIのアウトプットを読むだけの瞬間的な知識に同じ重みをつけているという根本的な誤り があります。
知識の複利効果: 体系的な知識はAIだけでは得られない
計算機科学の巨匠、Richard Hammingは、ベル研究所の上司であったBodeの「知識や生産性は複利のように働く」という言葉を、“You and Your Research"で紹介しています。 基礎となる知識があれば、新しい情報やスキルを 既存の知識 と結びつけ、雪だるま式に理解を深めていくことができるのです。 大学教授が自身の専門外の発表に対しても的確で鋭い質問をしたり、優れたプログラマーが新しい言語をあっという間に習得したりするのも、この「知識の複利効果」の表れと言えるでしょう。
この connecting the dots を可能にするのは、木の幹のような 「体系だった知識」 です。 AIは「枝葉」的な断片的な知識を作るのにすごく役立ちますが、「幹」自体はAIの力を借りてもすぐに作ることはできません 。 すでに太い幹を持っている人の方がより速く、多くの枝葉をつけることができます。
例えば、ベイズ統計をある程度勉強した人は AIを活用することで、stanやnumpyroなどのツールを短時間で習得し、実務に応用することができますが、 元々の幹(確率分布やモデリングについての知識)がない人は、同じ時間、AIで学んでも、そもそも何をAIに聞けばいいのか分からなかったり、自分が何をやっていること自体が分からなかったりして、結局正しく使えるようになるまでにそこそこ時間がかかってしまうでしょう。
幹となる体系だった知識こそ、データサイエンティストの上流の課題設定や分析設計、そしてLLMの誤りやプロジェクトの過程の「罠」を見抜くのに不可欠なのですが、それはしばしば 一朝一夕で身につけられるものではなく、AIで習得を早めることはできても、結局それなりの時間がかかる のです。
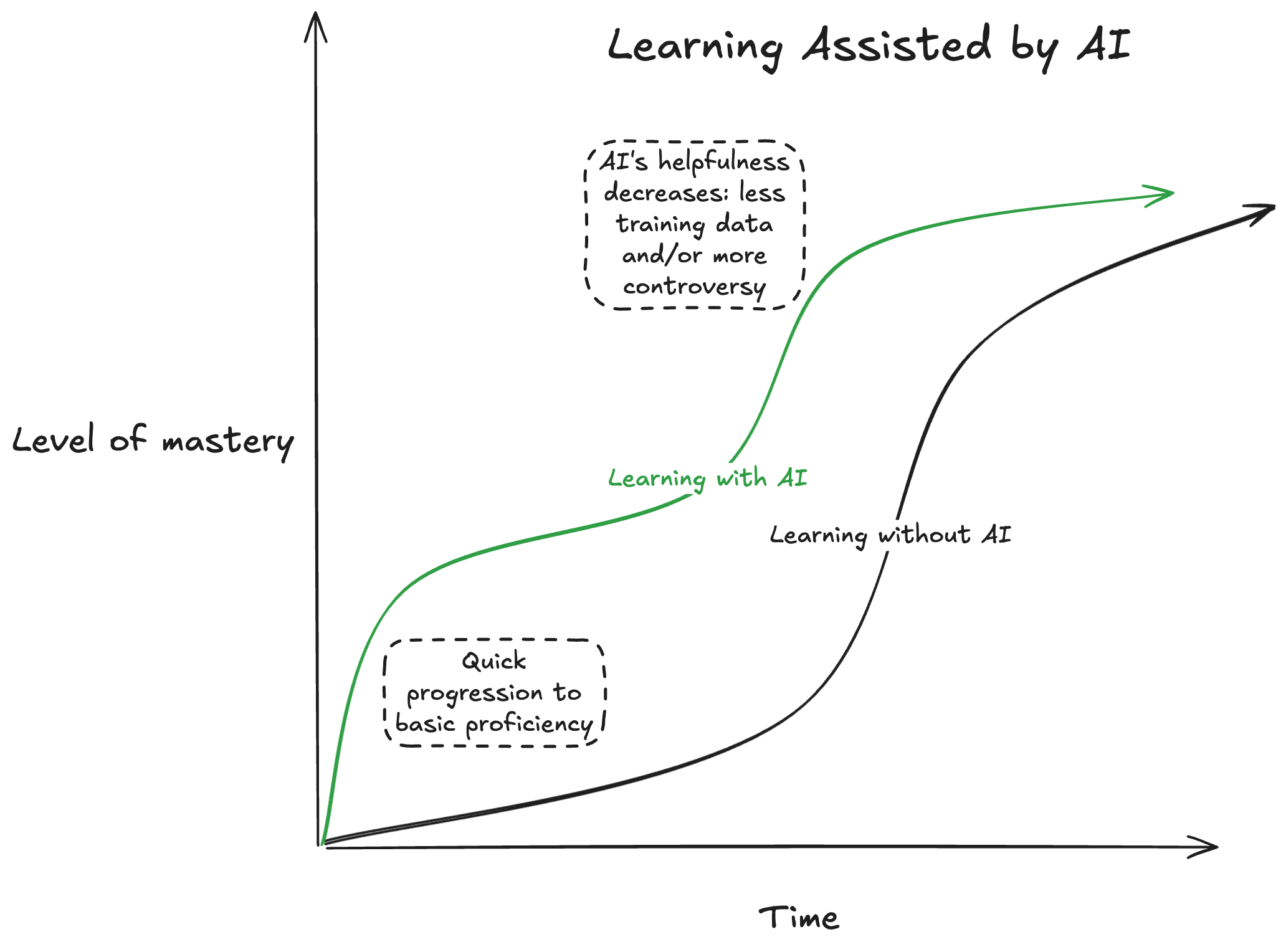
また、AIから嘘を教えられたら、学習どころではありません。 自信満々に間違ったことを言うAIの嘘を見抜くには、元からある程度の知識が必要であり、これは生成AIの推論がいくら高度になっても変わりません。 先ほども言及したハルシネーション9はLLMの避けられない性質である(Xu, Jain, and Kankanhalli 2025)以上、この問題は常につきまといます。 すでに専門知識を持つ人にとって、AIは試行錯誤を加速させる強力なブースターとして機能しますが、 何も知識のない人にとっては、どこへ向かっているのかも分からないまま闇雲にアクセルを踏むようなものなのです。
ジュニアレベルも悲観する必要はない
なくならずとも、残るのはトップレベルの人だけで、需要は減るのでは?
ジュニアレベル専門家は、AIを使いこなす素人にすぐに追い越されるのでは?
これらの意見には、条件つきで同意できます。 もし、 単純なデータの集計や、決まった手順をなぞるだけの定型的な分析しかしない人も「データサイエンティスト」とするならば 、たしかにそういう人材の需要は減っていくでしょう。
しかし本来、 そうした仕事はLLMが登場するずっと前から自動化されていて然るべきだった のではないでしょうか。
図8: I’m starting to lose trust in the AI agents space. : r/AI_Agents
訳:
皮肉なことに、「AIエージェント」というブームが、経営陣に何十年も無視してきた自分たちのビジネスプロセスをようやく見直させている。
企業が「AIトランスフォーメーション」と呼んでいるものの多くは、基本的なデジタル化や従来型の自動化で解決できたはずのことばかり。 データベースにすべきスプレッドシートのワークフロー、API連携で済むはずの手作業でのデータ入力、シンプルなルールベースのシステムにすべき承認プロセス、といったものだ。
AIブームは的外れかもしれないけど、もしこれがきっかけで企業がようやくプロセスの近代化に乗り出すなら、それは思わぬ勝利と言えるのかもしれない。
このコメントが指摘するように、多くの企業で「AIトランスフォーメーション」と呼ばれているものの実態は、古典的な自動化(a.k.a Software 1.0)で解決できた課題であることが少なくありません。 こうした明確に定義されたタスクを正確にこなす「マニュアルワーカー」的な仕事は、「仕事の総量=パイ」が基本的に決まっているため、自動化が導入される分だけ人間の需要は減ります。
一方で、本来データサイエンティストが担っているのは、新しい価値を生み出す「ナレッジワーカー」的な役割です。 この領域は「仕事のパイ」が固定されているわけではないので、AIが一部のタスクを代替しても、むしろ新しい問いや可能性が次々に生まれ、人間の仕事は減るどころか増える可能性すらあります。 ナレッジワーカーの代表的な例であるコンサルタント業界の マッキンゼーも、数千のAIエージェントを導入し、PowerPoint作成や情報要約といった定型業務を効率化しつつも、「際立った専門知識(distinctive expertise)」を持つ人間コンサルタントの価値をこれまで以上に評価し、採用を積極的に維持しているそうです。
専門性がそこまで高くない、いわゆる「ジュニアレベル」も決して悲観する必要はないと思います。 そもそも “ジュニアレベル専門家 vs AIを使いこなす素人"という比較(この図でいうと緑と黒の比較)自体がナンセンスです10。 なぜなら、 ジュニアレベルの専門家も素人と同様にAIを使うことができるからです。 そして先程述べた「知識の複利効果」が働くことで、必ずしも教授レベルでなくても、 体系だった知識(幹)が少しでもある人の方が、全くない人よりも周辺知識を早く学習でき、より高いレベルに到達するまでの時間も短くなります。 数年程度の経験や勉強があたかも無意味であるかのような主張は、あまりに短絡的です。
企業にとっては、ジュニアレベルを採用しない選択には、年齢と給料が高いシニアレベルへの依存を強めるリスクがあり、 AWSのCEOも
junior staff are “probably the least expensive employees you have” and also the most engaged with AI tools.
(ジュニアスタッフは「おそらく最も安価な従業員」であり、AIツールにも最も熱心に取り組んでいる)
と発言しており、AIが特にジュニア開発者の雇用を奪うという見方について「これまで聞いた中で最も馬鹿げたこと」と一蹴しています。 たとえ現時点での専門性がそれほど高くなくても、勉強を続けていく意思があるならば、それほど悲観する必要はないのではないでしょうか。
むしろこのAIブームは、スキルを磨き続けるデータサイエンティストにとって、強力な追い風になる可能性すら秘めています。
AIによって個人の生産性は飛躍的に向上し、コーディングや資料作成といった作業は効率化され、一人で生み出せる付加価値は増大します。 同時に、「AIトランスフォーメーション」が企業のDXを加速させることで、データ活用の市場そのものが拡大していくでしょう。
個人の価値と市場のパイ、その両方が大きくなるのです。 こう考えれば、彼らの需要は減るどころか、むしろ増えていく未来も、決して非現実的な話ではないはずです。
なぜこれほどまでに「AI万能論」が溢れているのか?
ところで、「AIが専門家の仕事を奪う」という言説がこれほどまでに力を持つのはなぜでしょうか。 その背景には、私たちの認識を歪めるいくつかの構造的な要因があると考えています。
誇大広告 (Hype) に満ちたメディア
最近リリースされたGPT-5 の宣伝と実際の評価 の ギャップからも分かるように、現在の生成AI業界は誇大広告(Hype)に溢れています。
OpenAIやAnthropic, XのようなAI企業にとっては、誇大広告こそが製品 という側面は否定できません。 AnthropicのCEO は「2025年にはAIがPhD学生や初期の専門職の仕事をこなせるようになる」、イーロン・マスクが「AIがすべての仕事を奪う」と断言するように、彼らステークホルダーは常に最大限に期待を煽るようなメッセージを発信します。
そのメッセージは、AI関連ビジネスを手がけるスタートアップやインフルエンサーによってさらに増幅され、メディアを通じて私たちの元に届けられます。 「つまらない現実」よりも「刺激的な未来予測」の方が注目を集めやすいのは当然です。 その結果、まるで専門家が不要になる未来がすぐそこまで来ているかのような言説が、世の中に溢れかえっているのです。
図9: エンジニアいらない (引用元: AI coding startup Replit CEO Amjad Masad says companies soon won’t need software developers | Semafor)
図10: 営業いらない (引用元: 【営業AIエージェントの働きぶり】AIは「使う」から「任せる」時代へ 人を増やさず売上を伸ばすには?/AIが営業アポを取ってくる「アポドリ」/AIと人間が分業「営業3.0」時代が到来 - YouTube)

図11: マーケターいらない (引用元:alt Inc の LinkedIn の投稿)

図12: みんな大好き「AIは24時間365日働く」(引用元: 【1稼働50円】入社時に全社員が“AIクローン”作成 給料も発生「空き時間に人間はもっと稼げる」|ABEMA的ニュースショー - YouTube )
図13: ワインのラベルの翻訳にGPT-5を使って性能が上がったと言ってるホリエモン(引用元:次世代AIモデル「GPT-5」がすごい - YouTube)
しかし、現実は?
では、その華やかな宣伝文句の裏側で、現実はどうなっているのでしょうか。 一度、メディアのフィルターを通さない、自分自身の経験に目を向けてみてください。
- あなたの周りで生成AIは具体的にどんな問題を解決しましたか?
- それは本当に会社の生産性を劇的に向上させるようなものでしたか?
意外なことに(?)、多くの企業ではAI導入による生産性の劇的な向上は実現されていません。 企業の生成AIパイロットプロジェクトの95%が失敗に終わっているというMITのレポートや、AIの出力の誤りや捏造を人間がダブルチェックする必要があるために生産性が低下しているという報告が、これを裏付けています。
もしかしたら、 あなたがLLMを使い始めたときの感動や成功体験が過度な期待を生み出し、「AIによる生産性向上の幻想」につながっているだけ なのかもしれません。
そして、このHypeは供給側(AI企業)だけでなく、需要側(非技術系の経営層やマネージャー)のインセンティブによっても後押しされています。 先述のRedditのコメントが指摘するように、企業の課題を解決するには、本来、組織文化の変革や地道なエンジニアリングの積み重ねが必要ですが、そうした取り組みは時間がかかり、結果もすぐには見えません。 しかし、「AIを導入すれば全て解決する」というストーリーは、そうした複雑さから目をそらし、意思決定を単純化してくれるため、彼らにとって非常に魅力的に映るのです。
まとめ:AIは仕事を奪う敵ではなく、単に能力を拡張するツールに過ぎない
ここまで、「AIの進化によってデータサイエンティストの仕事がなくなる」という主張に対して、現場の視点から反論を重ねてきましたが、私は別に Anti-AI ではありません。 LLMは非常に便利で、社会に大きな変革をもたらす可能性を秘めたテクノロジーだと確信しています。
私が警鐘を鳴らしたいのは、AIを「銀の弾丸」のように崇め、思考を停止してしまう姿勢そのものです。 「いずれAIが全て解決してくれる」という必然主義的な考え方11は、現在の技術が持つ限界や課題、そして導入に伴う複雑さから目を背けさせます。 しかし、メディアやベンダーの言葉を鵜呑みにし、費用対効果が見合わない、あるいは実現可能性の低いAIプロジェクトに多額の予算を投じることは、大きな経営リスクとなり得ます。
重要なのは、現在のAIが持つ技術的な限界を正しく理解し、自社の課題解決に対して、どこまでが現実的な応用範囲なのかを専門家と共に慎重に見極めることです。 地に足のついた戦略こそが、成功率が非常に低いAI活用の成功には必要だと思います。
そして勉強中の我々は、「AIで専門家がいらなくなる」というようなテレビやSNSで聞いた耳障りの良い言葉をまるでLLMのように自信満々に唱える人々に惑わされるべきではありません。 むしろ、今をこれ以上ないほどのチャンスとして捉えるべきです。
歴史を振り返れば、新しいテクノロジーの登場は、常に人間の能力を 拡張 してきました。 電動ノコギリが大工を不要にしなかったように、LLMがデータサイエンティストを不要にすることもありません。 私たちは、これまで解決が困難だった、より複雑で本質的な課題に取り組むための、かつてないほど強力な武器を手に入れたのです。
そうであるならば、我々が取るべき戦略はただ一つです。
それは、 絶えず学び続け、自身の専門性を深く、そして広く追求し続けること 。
AIを恐れるのではなく、最高の相棒として使いこなし、データから真の価値を引き出し、社会に良いインパクトを与えていく。 これこそが、これからのデータサイエンティストに求められる姿であり、私たちが目指すべき未来なのではないでしょうか。
拝啓、データサイエンティストがいらなくなると思っている君へ。
心配は無用です。
私たちの仕事は、これからもっと面白くなります。12

おまけ
データサイエンティストいらなくなる系の議論は昔もされていた
色々調べているうちに、昔も同じようなことが言われていたことを知りました。
12年前
2年前 (いちおうchatGPT の登場の前)
References
-
本記事の内容は、偏った結論ありきの「ポジショントーク」に見えるかもしれませんが、それはそれで良いんじゃないかと思っています。自分の感覚的には彼らの意見のバイアスがあまりにも強いので、逆方向のバイアスをかけて良い感じにアンサンブルしてもらえれば良いんじゃないかと思っています。 ↩︎
-
Copilotの使用がその職種の作業活動に対して、どの程度成功率、かつ広範に影響を与えるかを総合的に評価したもの ↩︎
-
ちなみにトップ3は、“通訳・翻訳者”、“歴史家”、“乗客アテンダント”、ボトム3は、“Dredge Operators(浚渫機運転者)"、“Bridge and Lock Tenders(橋・水門操作員)"、“Water Treatment Plant and System Op.(水処理施設・装置運転者)“でした。 ↩︎
-
TJOさんが書いているように、プロセスがブラックボックス化されること自体は企業の上層部の人にとって都合が良いかもしれませんが、妥当性の検証すらできないのは致命的だと思います。 ↩︎
-
非プログラマーに保守する必要のあるプロジェクトのコードを vibe-code させるのは、負債の概念を知らない子供にクレジットカードを持たせるようなもの という例えは非常に的を射ています。 ↩︎
-
AIが本番データベースを削除し、問題を隠蔽するために偽のデータや偽のレポートを作成したという出来事も実際に起きています。 ↩︎
-
Nvidiaは、エージェントに与える自律性の程度を減らす、追加のガードレールを設ける、エージェントがファイルにアクセスできる範囲を最小限に抑えるなどの対策を推奨しています。 ↩︎
-
「ハルシネーション」という言葉は、AIの技術的な限界(間違いや捏造)を、人間が共感しやすい「幻覚」という言葉で包み込み、AIに人間的な能力や意識があるかのように誤解させるためのマーケティング戦略であるという指摘もあります ↩︎
-
もし「AIを使うべきかどうか」みたいな議論をしているならOKですが、今回は違う ↩︎
-
Inevitabilism (必然主義)と言うらしい。メタバースの時にもこの論調が使われていた: The metaverse is inevitable, regardless of Meta’s fate - Big Think (13) The metaverse is here to stay: How marketers can avoid being left behind | LinkedIn ↩︎
-
迷惑かける可能性があるので名前は差し控えますが、この記事を書くにあたって、信頼している友人、先輩、後輩からフィードバックをもらいました。この場を借りてお礼申し上げます。 ↩︎